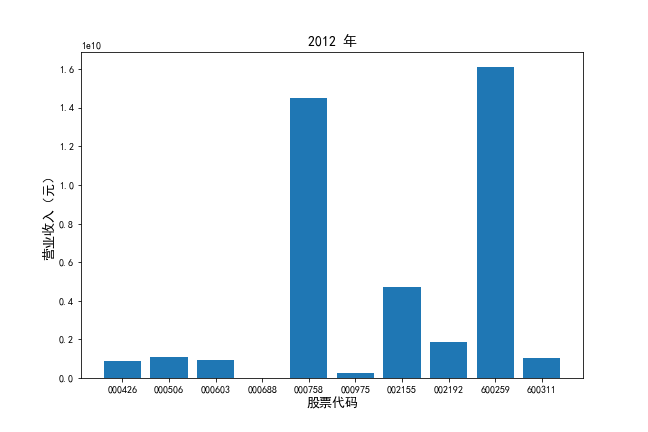
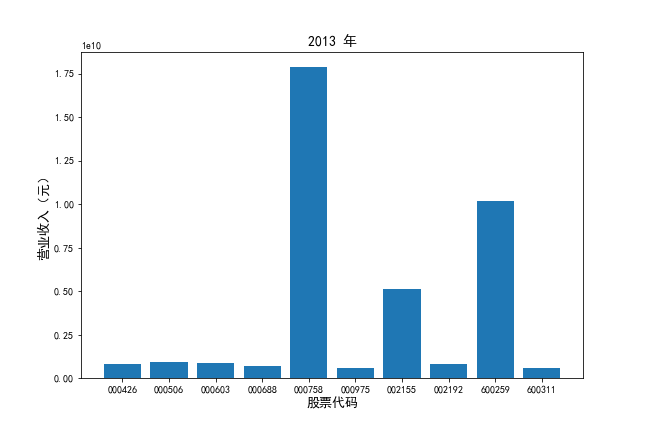
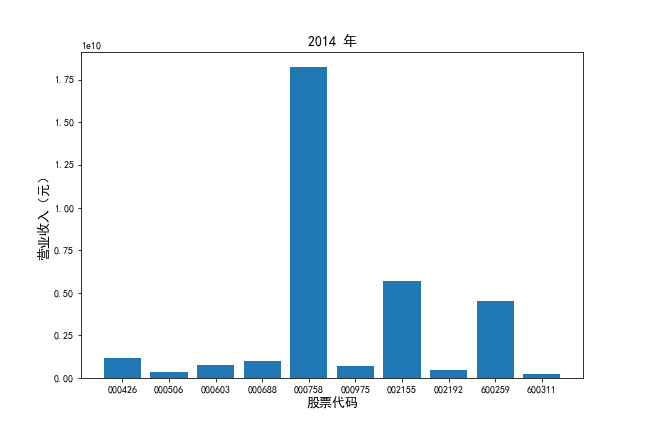
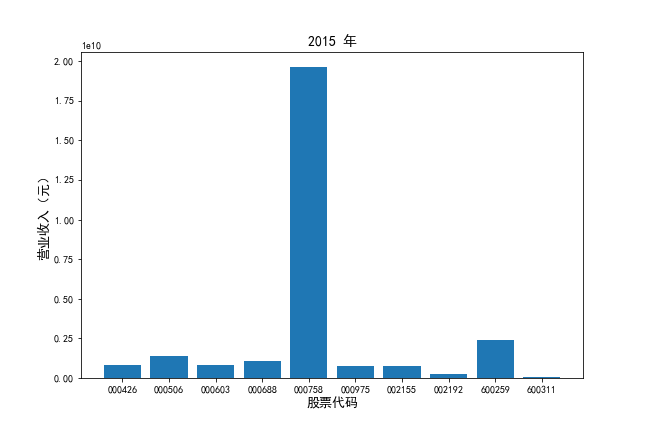
从行业分类结果文件中提取出自己行业的公司列表。
import pandas as pd
import pdfplumber
pdf = pdfplumber.open(r'C:\Users\DELL\Desktop\金融数据挖掘\大作业\行业分类.pdf')
page = pdf.pages[2]
table = page.extract_table()
df = pd.DataFrame(table)
df.to_excel(r'C:\Users\DELL\Desktop\金融数据挖掘\大作业\行业分类.xlsx', header=False, index=False)
df_c=pd.read_excel(r'C:\Users\DELL\Desktop\金融数据挖掘\大作业\行业分类1.xlsx',sheet_name='Sheet2',header=0,index_col=None,converters={'上市公司代码':str})
运用selenium模块访问证券交易所官网,输入公司名称,选择公告类别,输入时间范围,提取搜索结果代码写入html文件中。
from bs4 import BeautifulSoup
import re
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
browser = webdriver.Chrome()
browser.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
y_start = browser.find_element(By.CLASS_NAME,'input-left')
y_start.send_keys('2012' + Keys.RETURN)
y_end = browser.find_element(By.CLASS_NAME,'input-right')
y_end.send_keys('2022-05-01' + Keys.RETURN)
i=0
while i<9:
element = browser.find_element(By.ID,'input_code')
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
browser.find_element(By.LINK_TEXT,'年度报告').click()
element = browser.find_element(By.ID,'input_code')
element.send_keys(df_c.iloc[i,0] )
time.sleep(2)
element.send_keys(Keys.RETURN)
element = browser.find_element(By.ID,"disclosure-table")
time.sleep(2)
innerHTML = element.get_attribute("innerHTML")
time.sleep(2)
f = open("年报链接.html",'a',encoding='utf-8')
f.write(innerHTML)
time.sleep(2)
f.close()
browser.find_element(By.CSS_SELECTOR, ".btn-clearall").click()
i+=1
browser.quit()
from bs4 import BeautifulSoup
import re
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
i=9
while i<23:
browser = webdriver.Chrome()
browser.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
browser.find_element(By.ID, "inputCode").click()
element = browser.find_element(By.ID, "inputCode").send_keys(df_c.iloc[i,0])
time.sleep(2)
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
time.sleep(2)
browser.find_element(By.LINK_TEXT, "年报").click()
time.sleep(2)
# dropdown = browser.find_element(By.CSS_SELECTOR, ".show > .selectpicker")
# dropdown.find_element(By.XPATH, "//option[. = '年报']").click()
time.sleep(2)
element = browser.find_element(By.CLASS_NAME, 'common_con')
time.sleep(2)
innerHTML = element.get_attribute("innerHTML")
time.sleep(2)
f = open("年报链接.html",'a',encoding='utf-8')
f.write(innerHTML)
time.sleep(2)
browser.quit()
i+=1
解析爬取网页的源代码,获取相关信息及年报下载链接
def to_pretty(fhtml):
f = open(fhtml,encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open(fhtml[0:-5]+'-prettified.html', 'w', encoding='utf-8')
f.write(html_prettified)
f.close()
return(html_prettified)
html = to_pretty('SZ年报链接.html')
def txt_to_df(html):
# html table text to DataFrame
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds1 = [p2.findall(tr) for tr in trs[1:]]
tds = list(filter(None, tds1))
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
return(df)
df_txt = txt_to_df(html)
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
get_code = lambda txt: p_a.search(txt).group(1).strip()
get_time = lambda txt: p_span.search(txt).group(1).strip()
def get_link(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(df_txt):
prefix = 'https://disc.szse.cn/download'
prefix_href = 'https://www.szse.cn/'
df = df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
return(df)
df = get_data(df_txt)
过滤掉年报摘要、已取消年报等无用文件,筛选出修订版、更正版年报,下载。
#过滤年报摘要与已取消的年报
def tidy(df):
d = []
for index, row in df.iterrows():
title = row[2]
a = re.search("摘要|取消", title)
if a != None:
d.append(index)
name=row[1]
df1 = df.drop(d).reset_index(drop = True)
return df1
df = tidy(df)
df_1 = df[df['公告标题'].str.endswith('年度报告')]
df_2 = df[df['公告标题'].str.endswith('年报')]
df_3 = df[df['公告标题'].str.endswith('年报(修订版)')]
df_4 = df[df['公告标题'].str.endswith('年度报告(修订)')]
df_5 = df[df['公告标题'].str.endswith('年度报告-更正后')]
df_6 = df[df['公告标题'].str.endswith('年度报告(更正稿)')]
df_7 = df[df['公告标题'].str.endswith('年度报告(修订版) ')]
df_8 = df[df['公告标题'].str.endswith('年度报告(更正后) ')]
df_9 = df[df['公告标题'].str.endswith('年度报告(更正修订) ')]
df_10 = df[df['公告标题'].str.endswith('年度报告(更正后) ')]
df_temporary1 = df[-df['公告标题'].isin(df_1['公告标题'])]
df_temporary10 = df_temporary9[-df_temporary9['公告标题'].isin(df_10['公告标题'])]
df_final = df[-df['公告标题'].isin(df_temporary10['公告标题'])]
df_final = df_final.reset_index(drop=True)
df_final = df_final.replace('-',None)
#下载年报
import requests
for i in range (0,85):
r = requests.get(df['attachpath'][i], allow_redirects=True)
time.sleep(2)
f = open(df['证券代码'][i]+df['公告标题'][i]+'.pdf', 'wb')
f.write(r.content)
f.close()
r.close()
import fitz
import re
import pandas as pd
class NB_data():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages, jie_title = {}, {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '会计数据和财务指标摘要']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“会计数据和财务指标摘要”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('主要会计数据和财务指标.*?营业收入', re.DOTALL)
target_page = ''
for i in range(2):
page = self.doc[pages[0]+i]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = pages[0]+i; break
if target_page == '':
Warning('没找到“主要会计数据和财务指标”页')
self.key_fin_data_page = target_page
return(target_page)
def parse_revenue_table(self):
page_number1 = self.key_fin_data_page
page_number2 = self.key_fin_data_page +1
page1 = self.doc[page_number1]
page2 = self.doc[page_number2]
txt1 = page1.get_text()
txt2 = page2.get_text()
txt = txt1 + txt2
#
pt = '(.*?)(20\d{2} 年) \s*(20\d{2} 年 )\s*(.*?)\s*(20\d{2} 年 )\s*'
pt = '(?<=主要会计数据和财务指标)' + pt + '(?=营业收入)' # 向左、右看
p2 = re.compile(pt, re.DOTALL)
title = p2.findall(txt)[0] # 获取标题行
lst = list(title)
lst[0] = '项目'
title = tuple(lst)
title = [t.replace('\n','') for t in title] # 替换可能的标题表格内换行
#
number = '-?[\d,]+.\d+'
pentage = '-?[\d.%]+'
pr = ('(\w+[(\w+(/)?\w+)]*)\s+(%s)\s+(%s)\s+(%s)\s+(%s)\s+' %(number,
number,
pentage,
number))
# pr = '(\w+)\s*(-?[\d,]*)\s*(-?[\d,]*)\s*(-?[\d.]*%)\s*(-?[\d,]*)'
pr = '(?<=\n)' + pr + '(?=\n)' # 向左、右看
p = re.compile(pr)
txt = txt[:txt.find('总资产')]
data = p.findall(txt)
#
df = pd.DataFrame({title[0]: [t[0] for t in data],
title[1]: [t[1] for t in data],
title[2]: [t[2] for t in data],
title[3]: [t[3] for t in data],
title[4]: [t[4] for t in data]})
# return((df,title))
self.revenue_table = df
return(df)
def parse_revenue_table_6(self):
page_number1 = self.key_fin_data_page
page_number2 = self.key_fin_data_page +1
page1 = self.doc[page_number1]
page2 = self.doc[page_number2]
txt1 = page1.get_text()
txt2 = page2.get_text()
txt = txt1 + txt2
#
pt = '(.*?)(20\d{2}\s*年)\s*(20\d{2}\s*年)\s*(.*?\n.*?\n.*?\n.*?)\s*(20\d{2}\s*年)\s*'
# pt = '(?<=主要会计数据)' + pt + '(?=营业收入)' # 向左、右看
p2 = re.compile(pt, re.DOTALL)
title = p2.findall(txt)[0] # 获取标题行
lst = list(title)
lst[0] = '项目'
title = tuple(lst)
title = [t.replace('\n','') for t in title] # 替换可能的标题表格内换行
#
number = '-?[\d,\s*]+.\s*\d+'
pentage = '-?[\d.\d]+'
pr = ('(\w+[(\w+(/)?\w*)]*)\s*(%s)\s*(%s)\s*(%s)\s*(%s)\s*(%s)\s*(%s)\s*' %(number,
number,
number,
pentage,
number,
number))
# pr = '(\w+)\s*(-?[\d,]*)\s*(-?[\d,]*)\s*(-?[\d.]*%)\s*(-?[\d,]*)'
pr = '(?<=\n)' + pr + '(?=\n)' # 向左、右看
p = re.compile(pr)
txt4 = txt[txt.find('主要会计数据'):txt.find('归属于上市公司')]
data1 = p.findall(txt4)
#
df_r = pd.DataFrame({title[0]: [t[0] for t in data1],
title[1]: [t[1] for t in data1],
title[2]: [t[2] for t in data1],
title[3]: [t[3] for t in data1],
title[4]: [t[4] for t in data1]})
#
percent = '-?\d+.\d+'
pr2 = ('(\w+[(\w+(/)?\w*)]*)\s*(%s)\s*(%s)\s*(%s)\s*(不适用)\s*(%s)\s*(%s)\s*' %(percent,
percent,
percent,
percent,
percent))
pr2 = '(?<=\n)' + pr2 + '(?=\n)'
p3 = re.compile(pr2)
txt3 = txt[txt.find('主要财务指标'):txt.find('稀释')]
data2 = p3.findall(txt3)
df_pe = pd.DataFrame({title[0]: [t[0] for t in data2],
title[1]: [t[1] for t in data2],
title[2]: [t[2] for t in data2],
title[3]: [t[3] for t in data2],
title[4]: [t[4] for t in data2]})
df = df_r.append(df_pe)
self.revenue_table = df
return(df)
def table_processing(self):
df_t = self.revenue_table
df1 = df_t[df_t.iloc[:,0].str.startswith('营业')]
df2 = df_t[df_t.iloc[:,0].str.startswith('基本')]
df_3 = df1.append(df2)
df_3 = df_3.drop(df_3.iloc[:,2:5],axis=1)
df_3 = df_3.set_index(df_3['项目'])
df_3 = df_3.drop(columns='项目')
self.annual_revenue_table = df_3
return(df_3)
class NB_info():
'''
解析上市公司年度报告
'''
def __init__(self,pdf_filename):
self.doc = fitz.open(pdf_filename)
self.pdf_name = pdf_filename
self.get_toc()
self.jie_pages_title()
self.get_key_findata_pages()
self.get_target_page()
def get_toc(self):
jie_zh = '一二三四五六七八九十'
p = re.compile('(第[%s]{1,2}节)\s+(\w[、\w]*\w)' % jie_zh)
toc = []
for page in self.doc:
txt = page.get_text()
match = p.findall(txt)
if len(match) != 0:
first_match = match[0]
toc.append((first_match, page.number))
#
self.toc = toc
def jie_pages_title(self):
toc = self.toc
jie_pages, jie_title = {}, {}
for t in toc:
jie, title, pageNumber = t[0][0], t[0][1], t[1]
if jie in jie_pages:
jie_pages[jie].append(pageNumber)
else:
jie_pages[jie] = [pageNumber]
jie_title[jie] = title
self.jie_pages = jie_pages
self.jie_title = jie_title
def get_key_findata_pages(self):
pages = ''
jie_title = self.jie_title
titles = ['公司简介和主要财务指标', '公司简介']
for jie in jie_title:
title = jie_title[jie]
if title in titles: pages = self.jie_pages[jie]; break
if pages == '':
Warning('没有找到“公司简介和主要财务指标”或“公司简介”')
#
self.key_fin_data_pages = pages
return(pages)
def get_target_page(self):
pages = self.key_fin_data_pages
pattern = re.compile('公司信息.*?股票简称', re.DOTALL)
target_page = ''
for i in range(2):
page = self.doc[pages[0]+i]
txt = page.get_text()
matchObj = pattern.search(txt)
if matchObj is not None:
target_page = pages[0]+i; break
if target_page == '':
Warning('没找到“公司简介”页')
self.key_fin_data_page = target_page
return(target_page)
def parse_com_info_table(self):
page_number = self.key_fin_data_page
page = self.doc[page_number]
txt = page.get_text()
pr1 = '(?<=\n)股票简称 \n(\w+) \n股票代码 \n(\d{6}) (?=\n)' # 向左、右看
pr2 = '(?<=\n)办公地址 \n(\w*\s*\d*\s*\w*) (?=\n)'
pr3 = '(?<=\n)公司网址\s*(.*?)\s*(?=\n)'
p1 = re.compile(pr1)
p2 = re.compile(pr2)
p3 = re.compile(pr3)
data1 = p1.findall(txt)
data2 = p2.findall(txt)
data3 = p3.findall(txt)
df = pd.DataFrame({'股票简称': [t[0] for t in data1],
'股票代码': [t[1] for t in data1],
'办公地址': [data2[0]],
'公司网址': [data3][0]})
# return((df,title))
self.info_table = df
# return(df)
return(df)
text1 = NB_data('0004262012年年度报告.pdf')
df1 = text1.parse_revenue_table()
df1 = text1.table_processing()
text_1 = NB_info('0004262012年年度报告.pdf')
data_1 = text_1.parse_com_info_table()
df1 = pd.merge(df1,df10,on=['项目'])
data_1 = data_1.append(data_10)
df1.to_excel(r"C:\Users\DELL\Desktop\金融数据挖掘\大作业\000426\annual revenue.xls")
data_1.to_excel(r"C:\Users\DELL\Desktop\金融数据挖掘\大作业\000426\company infomation.xlsx")
import os
import pandas as pd
file_dir = r'C:\Users\DELL\Desktop\金融数据挖掘\大作业'
#revenue table
lst = []
for dirpath, dirnames, filenames in os.walk(file_dir):
for file in filenames:
if os.path.splitext(file)[1] == '.xls' and os.path.splitext(file)[0] == 'annual revenue':
h = os.path.join(dirpath, file)
lst.append(h)
# print (dirpath)
df = pd.DataFrame({})
for i in range(21):
df=df.append(pd.read_excel(lst[i],sheet_name='Sheet1',header=0,index_col=None))
df1 = df[df.iloc[:,0].str.startswith('营业收入')]
df1 = df1.reset_index()
df1 = df1.drop(columns='index')
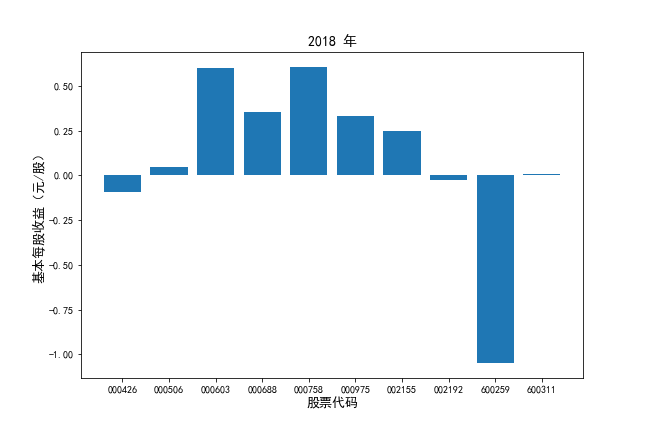
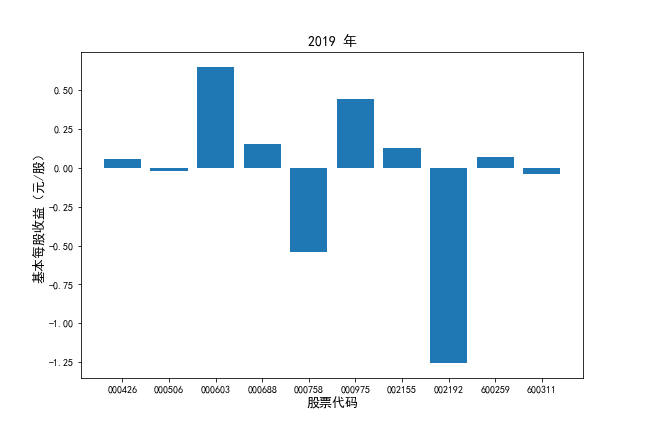
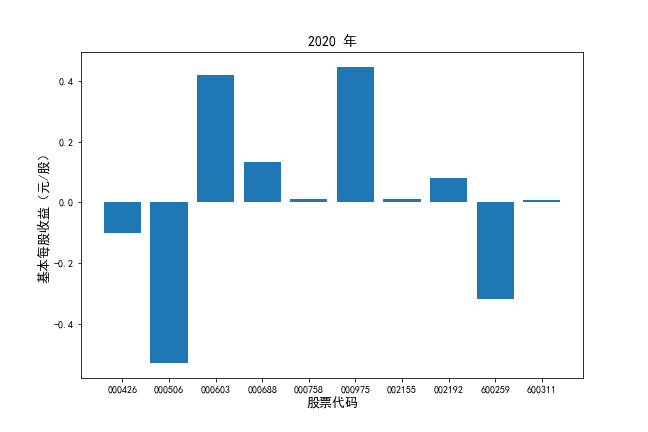
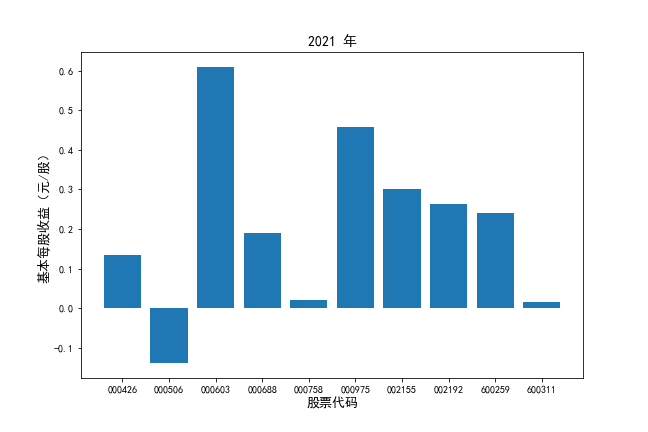
df2 = df[df.iloc[:,0].str.startswith('基本每股收益')]
df2 = df2.reset_index()
df2 = df2.drop(columns='index')
df3 = pd.read_excel(r'C:\Users\DELL\Desktop\金融数据挖掘\大作业\行业分类1.xlsx',sheet_name='Sheet2',header=0,index_col=None,dtype=object)
df1.index = df3['上市公司代码']
df2.index = df3['上市公司代码']
df1.to_csv(r'C:\Users\DELL\Desktop\金融数据挖掘\大作业\total revenue table.csv')
df2.to_csv(r'C:\Users\DELL\Desktop\金融数据挖掘\大作业\total pe table.csv')
#company infomation
lst1 = []
for dirpath, dirnames, filenames in os.walk(file_dir):
for file in filenames:
if os.path.splitext(file)[1] == '.xlsx' and os.path.splitext(file)[0] == 'company infomation':
k = os.path.join(dirpath, file)
lst1.append(k)
df_0 = pd.DataFrame({})
for i in range(21):
df_0=df_0.append(pd.read_excel(lst1[i],sheet_name='Sheet1',header=0,index_col=None,dtype=object))
df_0 = df_0.reset_index()
df_0 = df_0.drop(df_0.iloc[:,0:2],axis = 1)
df_0.to_csv(r'C:\Users\DELL\Desktop\金融数据挖掘\大作业\total information table.csv')


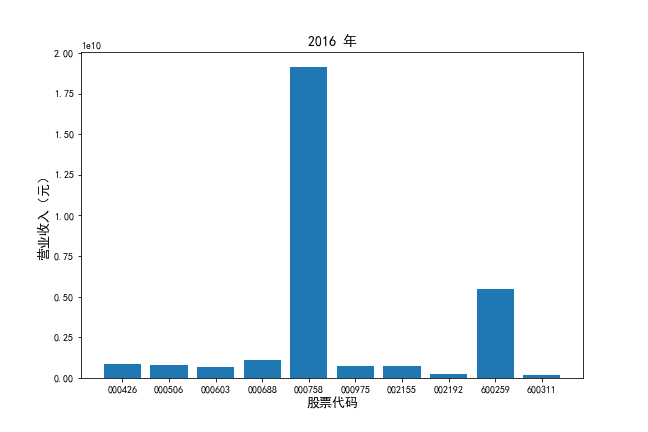
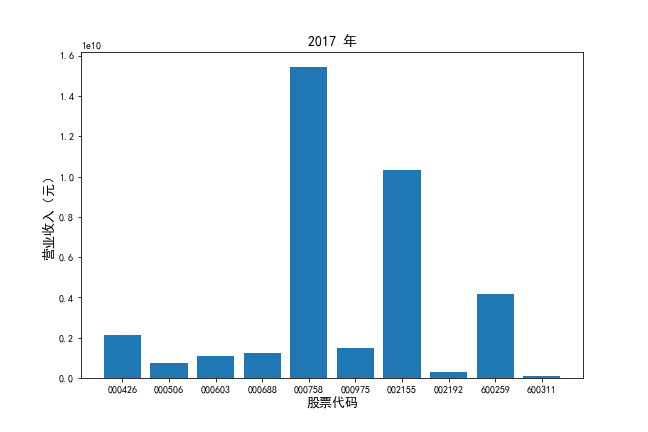
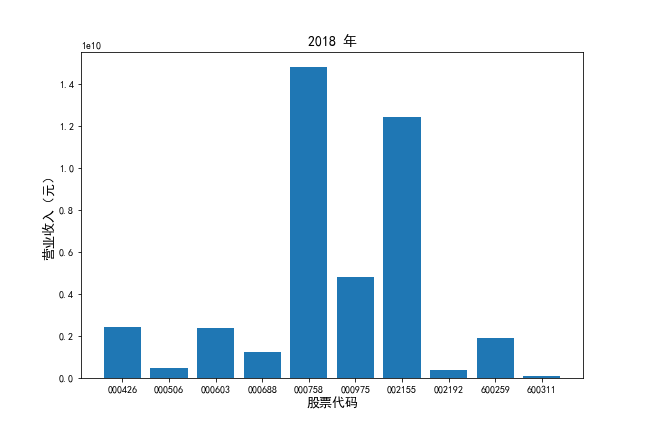
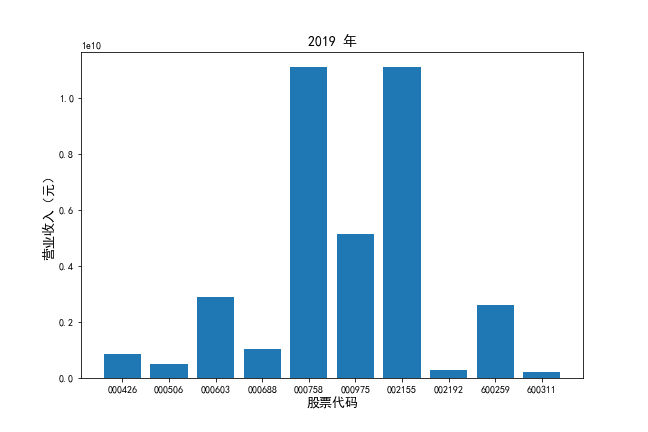
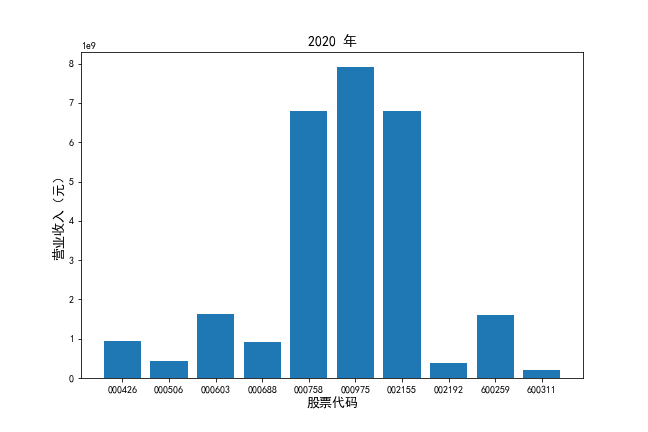
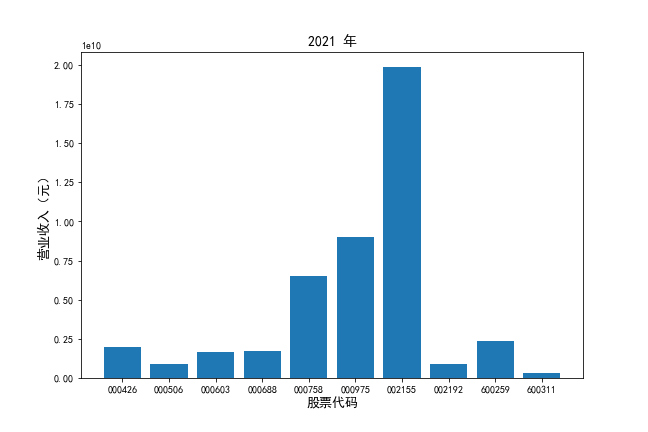
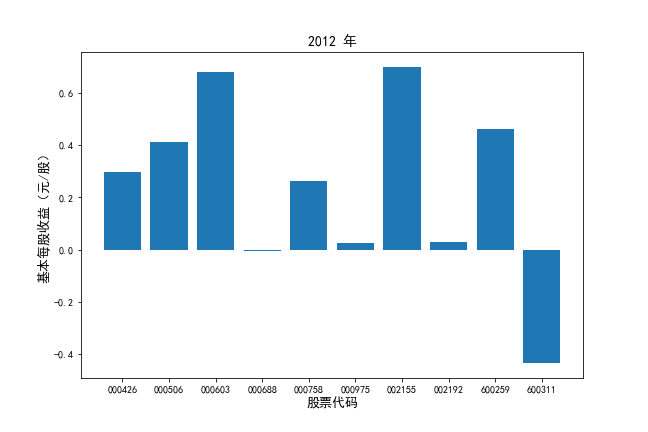
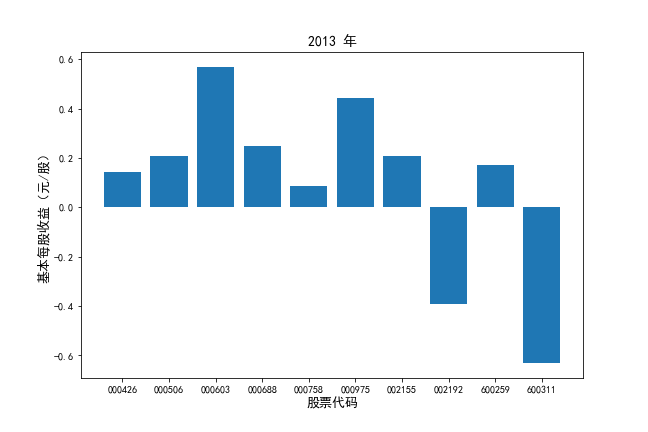
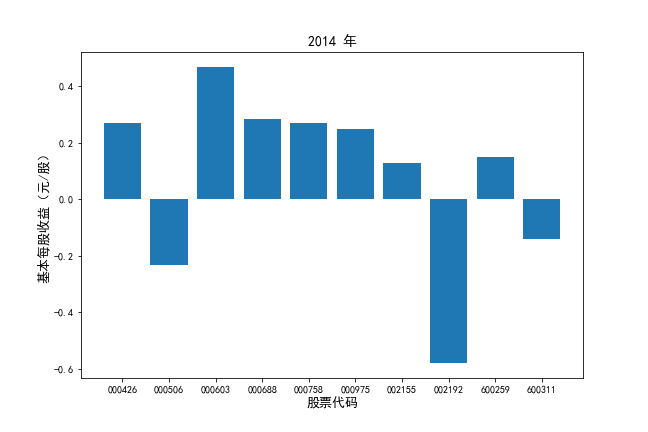
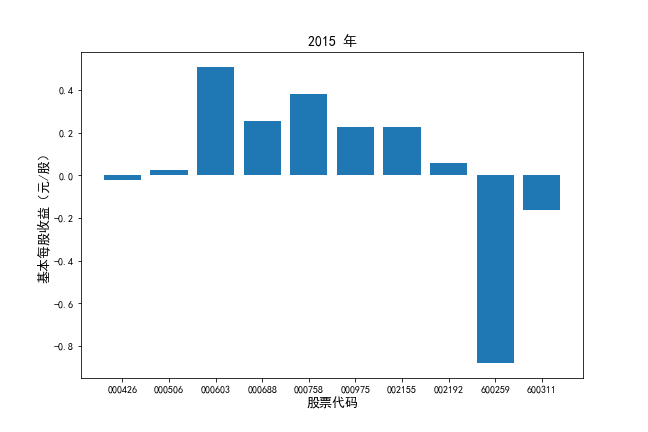
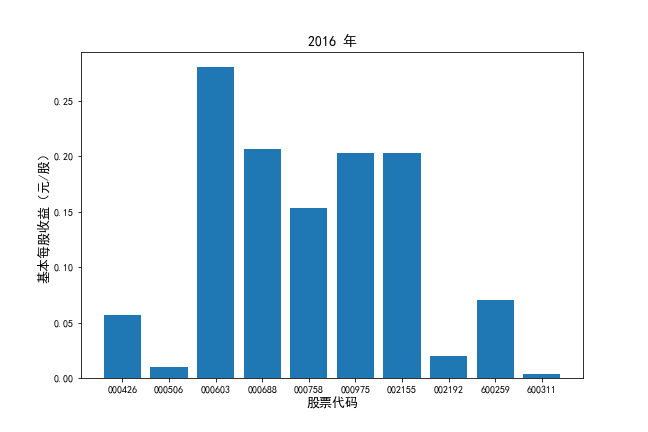
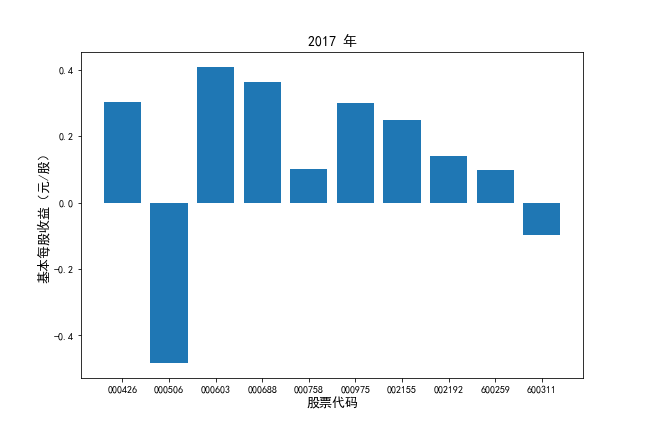
挑选营业收入最高的10家公司,绘制其“营业收入”和“基本每股收益”10年的时间序列图。
import numpy as np
import pandas as pd
from pylab import mpl
import matplotlib.pyplot as plt
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False
%matplotlib qt5
#纵向营业收入
df2 = pd.read_csv(r'C:\Users\DELL\Desktop\金融数据挖掘\大作业\total revenue table.csv')
df2 = df2.iloc[:,1:-1]
for i in range(11):
df2.iloc[i,2:] = pd.to_numeric(df2.iloc[i,2:]).round(2).astype(int)
for i in range(10):
plt.figure(figsize=(9,6))
ypoints = np.array(df2.iloc[i,2:])
xpoints = np.array(df2.columns)
xpoints = xpoints[2:]
plt.plot(xpoints,ypoints, marker = 'o')
plt.xlabel(u'年份',fontsize=13)
plt.ylabel(u'营业收入(元)',fontsize=13)
plt.title(df2.iloc[i,0],fontsize=14)
plt.show()
#纵向每股收益
df3 = pd.read_csv(r'C:\Users\DELL\Desktop\金融数据挖掘\大作业\total pe table.csv',dtype=object)
df3.to_excel(r'C:\Users\DELL\Desktop\金融数据挖掘\大作业\total pe table.xlsx')
df4 = pd.read_excel(r'C:\Users\DELL\Desktop\金融数据挖掘\大作业\total pe table.xlsx',dtype=object)
df4 = df4.iloc[:,1:-1]
for i in range(11):
df4.iloc[i,2:] = pd.to_numeric(df4.iloc[i,2:]).round(2).astype(int)
for i in range(10):
plt.figure(figsize=(9,6))
ypoints = np.array(df4.iloc[i,2:])
xpoints = np.array(df4.columns)
xpoints = xpoints[2:]
plt.plot(xpoints,ypoints, marker = 'o')
plt.xlabel(u'年份',fontsize=13)
plt.ylabel(u'基本每股收益(元/股)',fontsize=13)
plt.title(df4.iloc[i,0],fontsize=14)
plt.show()
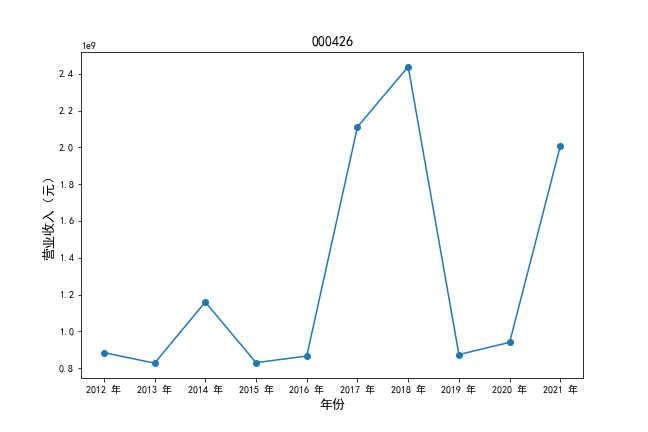
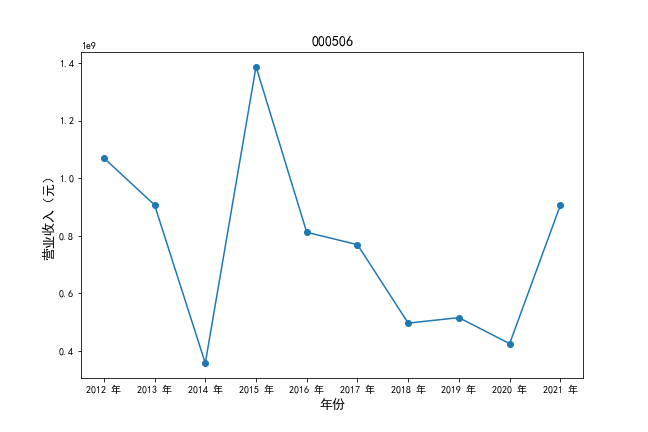
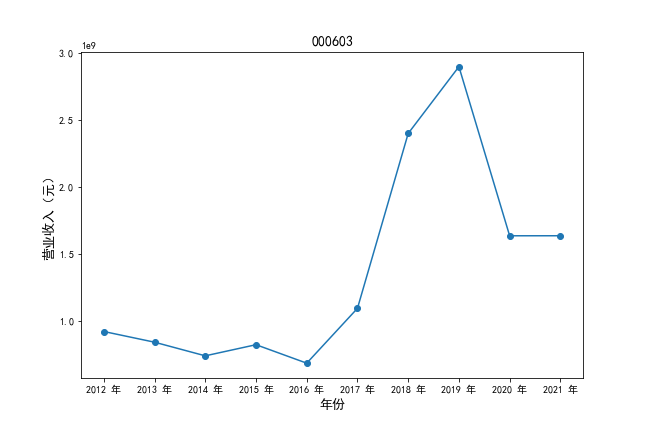
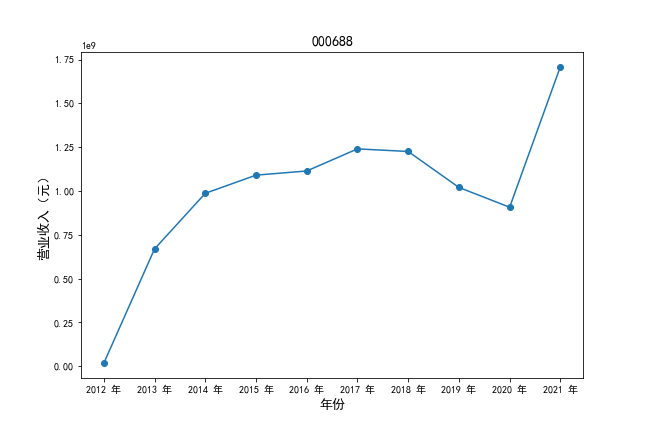
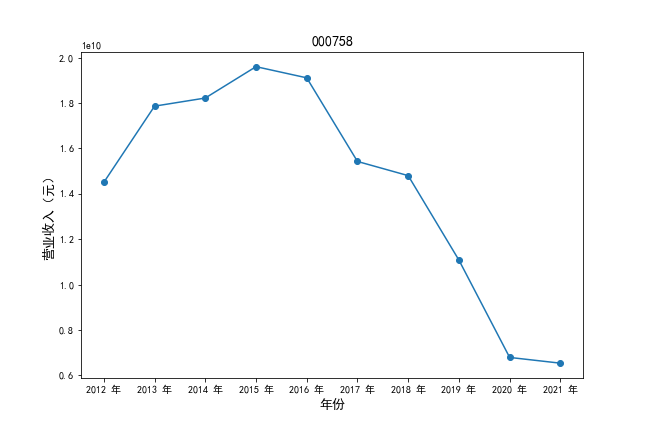
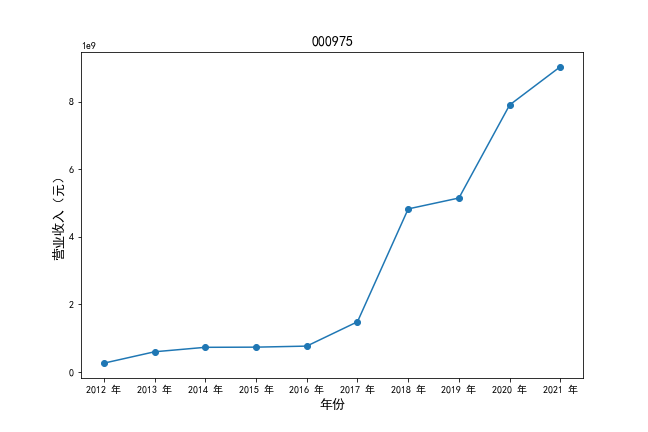
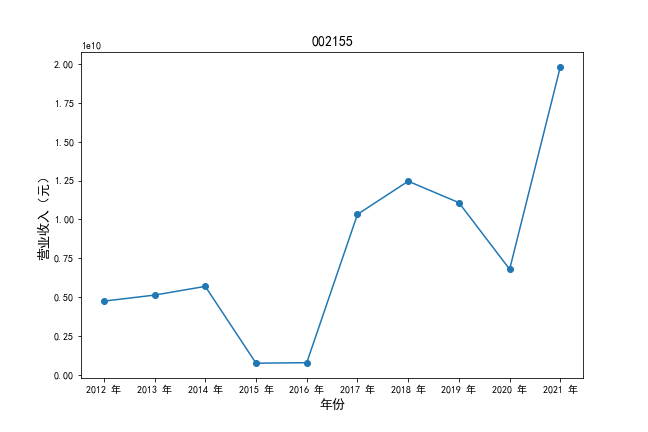
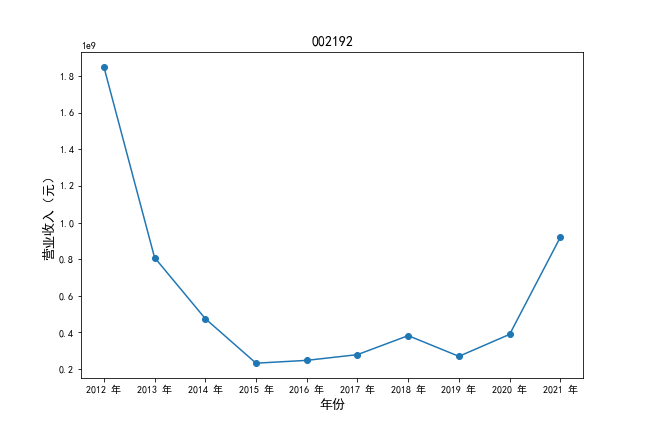
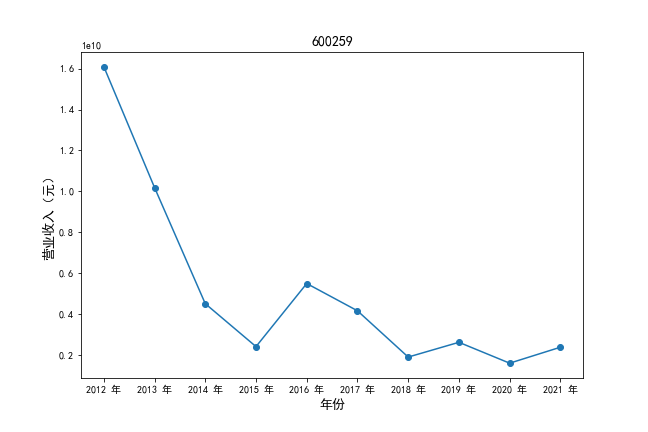
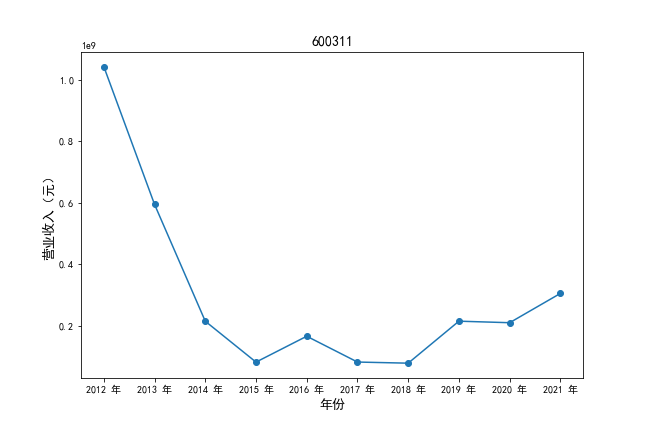
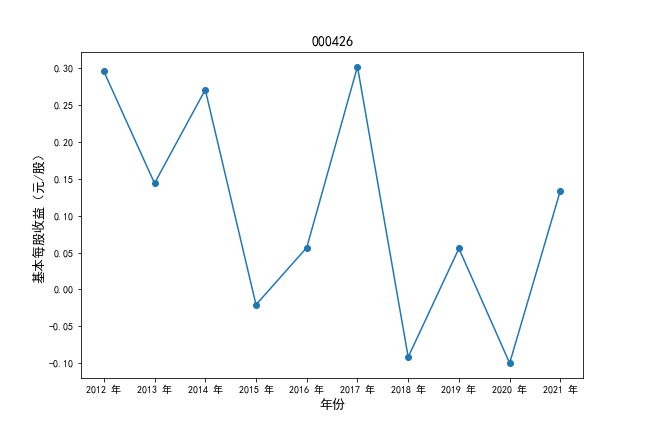
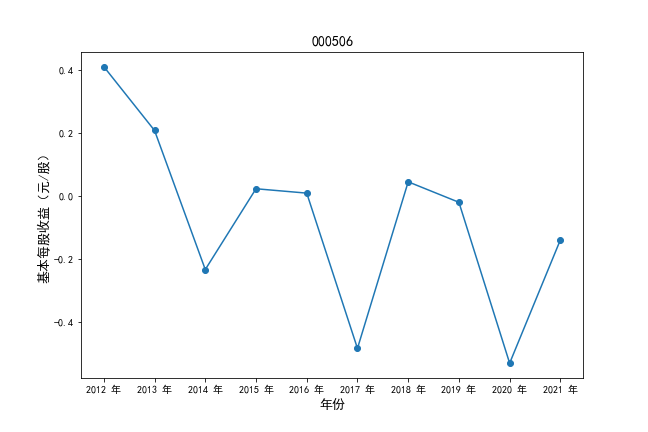
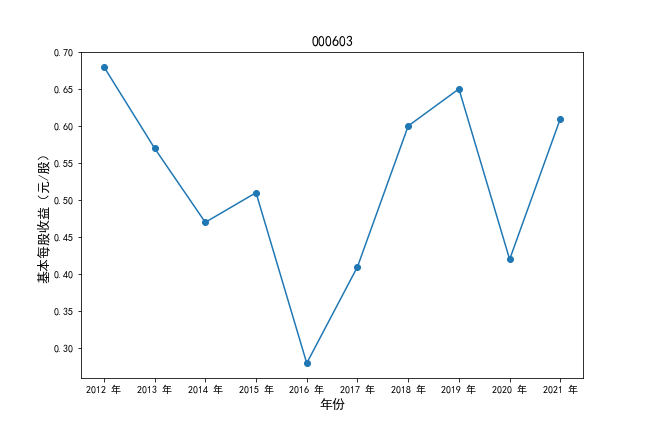
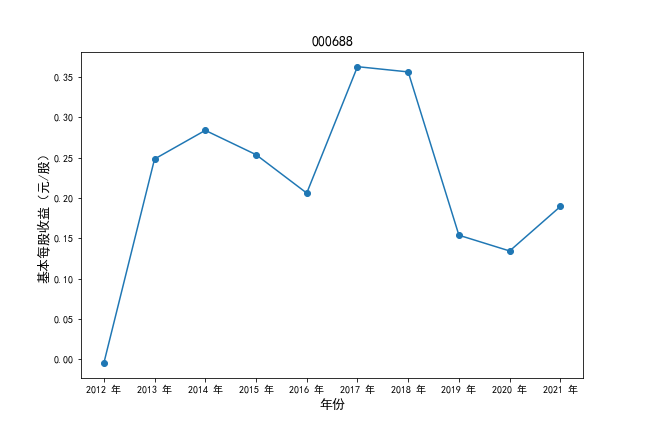
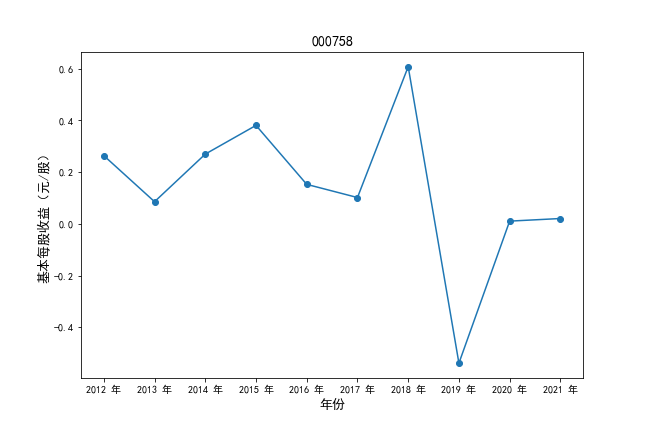
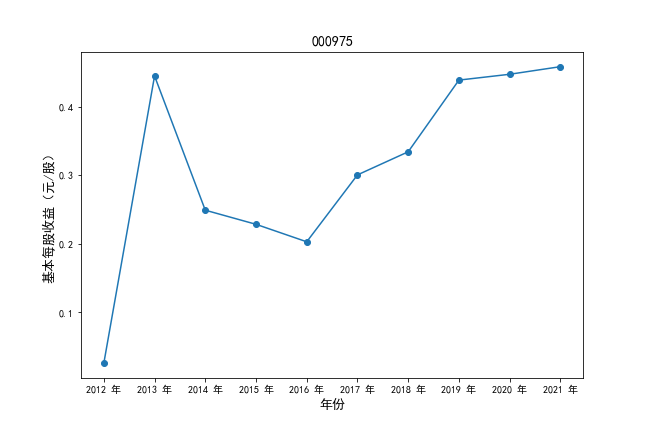
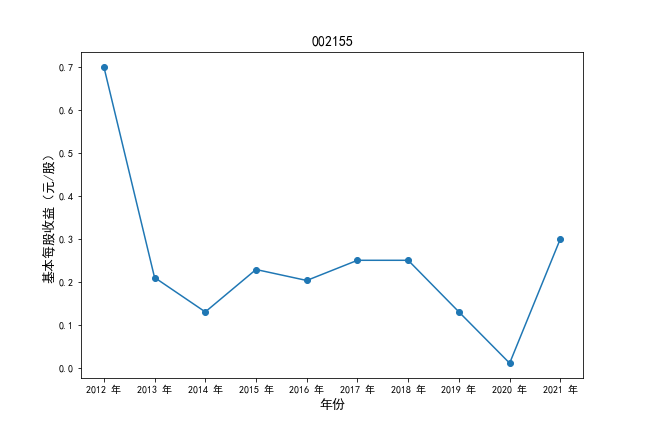
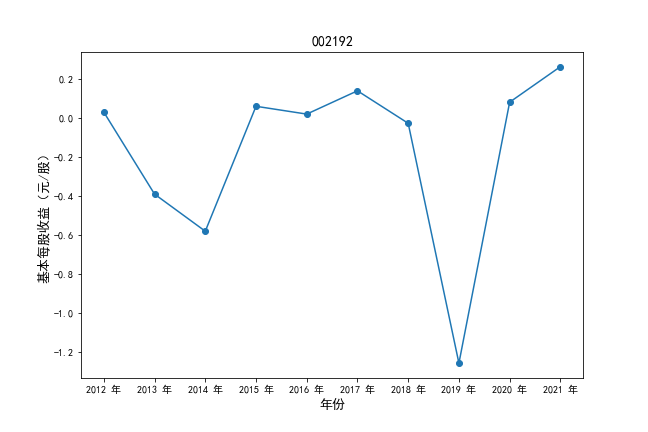
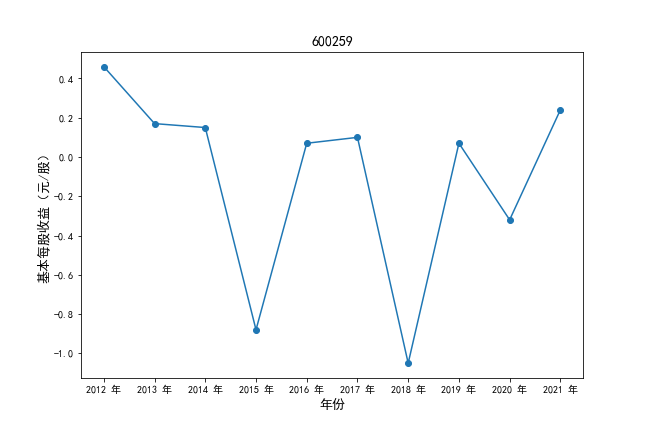
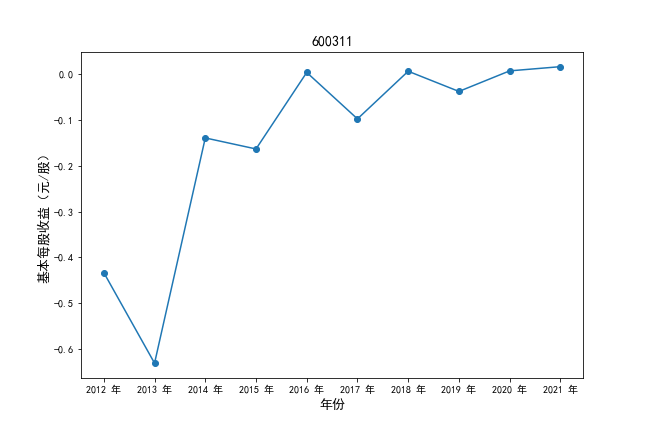
挑选营业收入最高的10家公司,对比每一年份各家公司“营业收入”和”基本每股收益。