import fitz
from bs4 import BeautifulSoup
import re
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import pdfplumber
import time
# 将证监会行业分类的pdf下载到本地,用pdfplumber提取表格
# 提取所需公司代码,并转成dataframe保存为excel文件
page = pdfplumber.open("/Users/xieqinyan/Desktop/金融数据获取与处理/证监会行业分类.pdf").pages[1] #获取第2页
table = page.extract_table()
df = pd.DataFrame(table)
df.columns = ['行业','行业代码','行业名称','公司代码','公司名称']
df = df.fillna(method='ffill')
df = df.iloc[1:,]
df1 = pd.DataFrame(df.loc[:,'行业代码'])
df2 = pd.DataFrame(df.loc[:,'公司代码'])
df3 = pd.DataFrame(df.loc[:,'公司名称'])
df = df1.join(df2)
df = df.join(df3)
df.index = df['公司代码']
df = df.loc['000552':'601918',]
df.to_excel('df_final.xlsx')
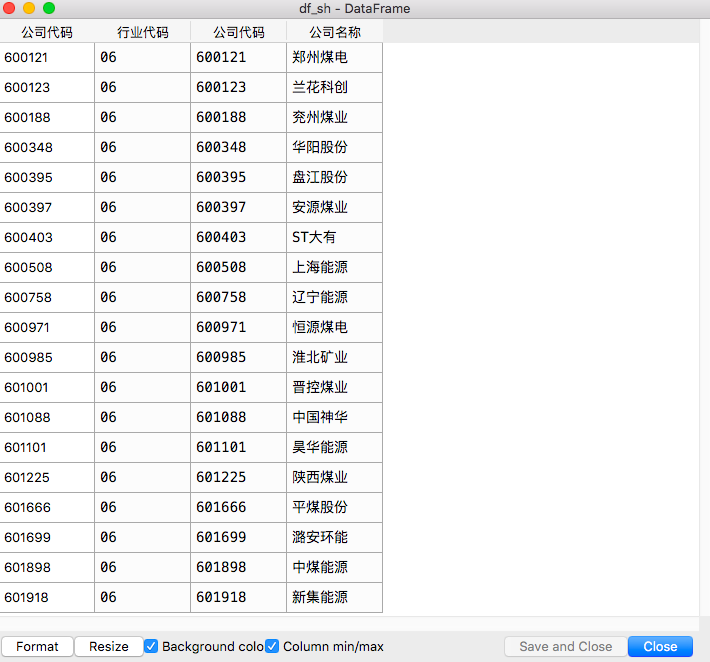
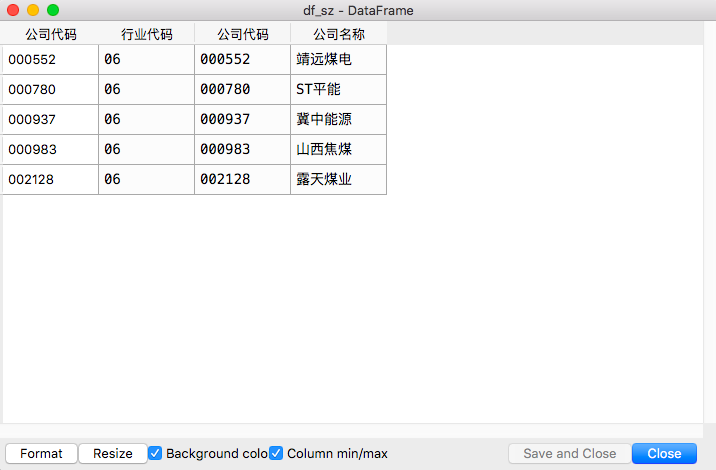
df_sz = df.loc['000552':'002128',]
df_sh = df.loc['600121':'601918',]
# 生成年报的html,并用正则表达式提取下载网址
# 因为上交所和深交所网站不一样,所以爬取的函数不一样,以下采取两个网站分开下载的办法
# 获取深交所年报的html文件
# 因为下载较耗费资源,持续下载容易报错,所以用time.sleep()使电脑休息
for i in range(1,len(df_sz)):
browser = webdriver.Chrome()
browser.get('http://www.szse.cn/disclosure/listed/fixed/index.html')
elem = browser.find_element(By.ID,'input_code')
elem.send_keys(df_sz.iloc[i,2] + Keys.RETURN)
time.sleep(2)
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
browser.find_element(By.LINK_TEXT,'年度报告').click()
time.sleep(2)
y_start = browser.find_element(By.CLASS_NAME,'input-left')
y_start.send_keys('2012' + Keys.RETURN)
y_end = browser.find_element(By.CLASS_NAME,'input-right')
y_start.send_keys('2022' + Keys.RETURN)
time.sleep(2)
element = browser.find_element(By.ID,"disclosure-table")
innerHTML = element.get_attribute("innerHTML")
time.sleep(4)
f = open("深交所年报.html",'a',encoding='utf-8')
f.write(innerHTML)
f.close()
browser.quit()
time.sleep(2)
# 获取上交所年报html文件
# (因为已经在spyder运行过,此处就不再运行了)
for i in range(0,len(df_sh)):
browser = webdriver.Chrome()
browser.get('http://www.sse.com.cn/disclosure/listedinfo/regular/')
time.sleep(2)
elem = browser.find_element(By.ID,'inputCode')
elem.send_keys(df_sh.iloc[i,1])
time.sleep(2)
browser.find_element(By.CSS_SELECTOR, ".sse_outerItem:nth-child(4) .filter-option-inner-inner").click()
time.sleep(2)
browser.find_element(By.LINK_TEXT,'年报').click()
time.sleep(2)
element = browser.find_element(By.CLASS_NAME, 'table-responsive')
time.sleep(2)
innerHTML = element.get_attribute("innerHTML")
time.sleep(2)
f = open("上交所年报.html",'a',encoding='utf-8')
f.write(innerHTML)
f.close()
browser.quit()
time.sleep(2)
生成的html的截图(以上交所为例)
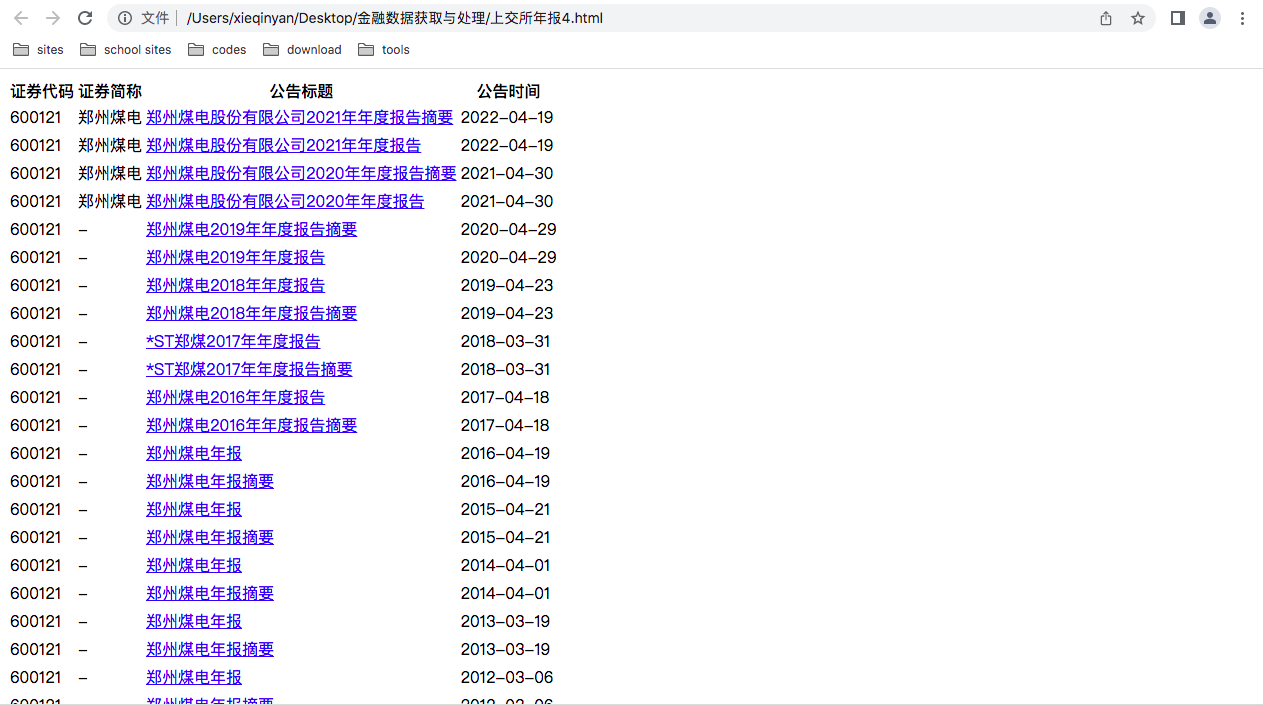
提取需下载的公司名称、股票代码的截图
# 规范化html,使每个标签更方便找
def to_pretty(fhtml):
f = open(fhtml,encoding='utf-8')
html = f.read()
f.close()
soup = BeautifulSoup(html)
html_prettified = soup.prettify()
f = open(fhtml[0:-5]+'-prettified.html', 'w', encoding='utf-8')
f.write(html_prettified)
f.close()
return(html_prettified)
sz = to_pretty('深交所年报.html')
sh = to_pretty('上交所年报.html')
# 从已经规范化的年报提取包含证券代码、简称、公告标题、公告时间的标签,并转为dataframe
def txt_to_df(html):
# html table text to DataFrame
p = re.compile('(.*?) ', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('(.*?)', re.DOTALL)
tds1 = [p2.findall(tr) for tr in trs[1:]]
tds = list(filter(None, tds1))
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
return(df)
df_txt1 = txt_to_df(sz)
df_txt2 = txt_to_df(sh)
# 利用正则表达式提取dataframe中各标签信息,并获取代码、简称、公告标题、公告时间
p_a = re.compile('(.*?)', re.DOTALL)
p_span = re.compile('(.*?)', re.DOTALL)
p_n = re.compile('\s+(.*?)\s+', re.DOTALL)
get_code = lambda txt: p_a.search(txt).group(1).strip()
get_name = lambda txt: p_span.search(txt).group(1).strip()
get_time = lambda txt: p_n.search(txt).group(1).strip()
def get_link(txt):
p_txt = '(.*?)'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
# 因为上交所和深交所的网址、标签对不一样,所以分开写
def get_data_sz(df_txt):
prefix_href = 'https://www.szse.cn/'
prefix = 'https://disc.szse.cn/download'
df = df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'公告时间': times
})
return(df)
def get_data_sh(df_txt):
prefix_href = 'http://static.sse.com.cn'
df = df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[1] for aht in ahts],
'href': [prefix_href + aht[0] for aht in ahts],
'公告时间': times
})
return(df)
df_1 = get_data_sz(df_txt1)
df_2 = get_data_sh(df_txt2)
# 上一步已得到较为规范的表格,但有些命名是:摘要、更新后、已取消等等的仍需过滤
# 过滤年报摘要与已取消的年报(深交所)
def filtered(df):
d = []
for index, row in df.iterrows():
title = row[2]
a = re.search("摘要|取消", title)
if a != None:
d.append(index)
name=row[1]
df_1 = df.drop(d).reset_index(drop = True)
return df_1
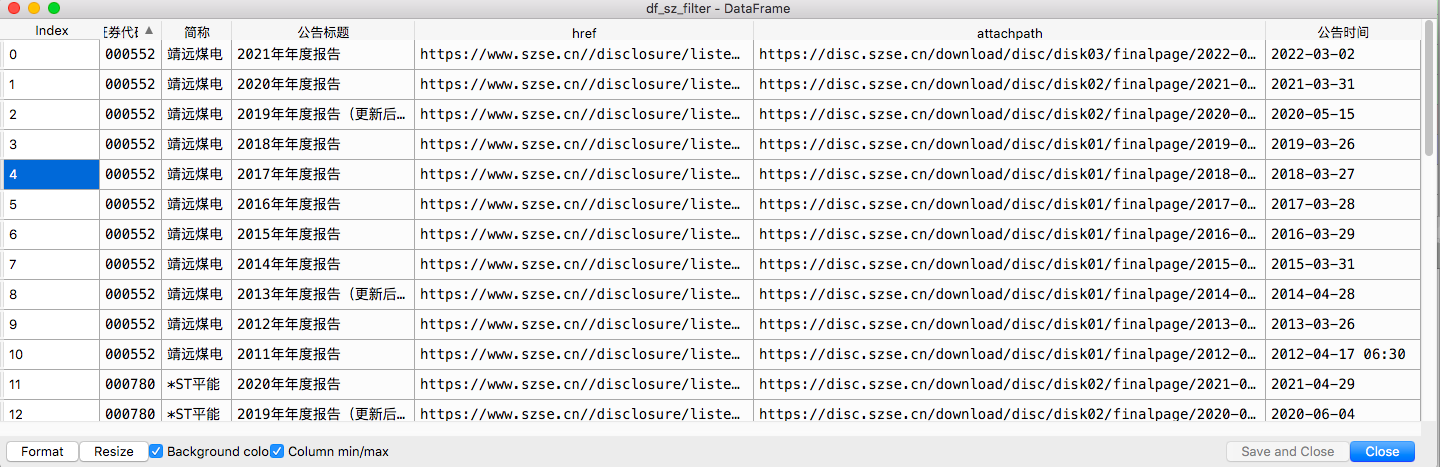
df_sz_filter = filtered(df_1)
df_sz_filter.to_excel('df_sz_filter.xlsx')
#过滤年报摘要与已取消的年报(上交所):因为上交所年报命名不甚规范,所以采取删去不需要的年报的方法
df_21 = df_2[df_2['公告标题'].str.endswith('年度报告')]
df_22 = df_2[df_2['公告标题'].str.endswith('年报')]
df_23 = df_2[df_2['公告标题'].str.endswith('年报(修订版)')]
df_24 = df_2[df_2['公告标题'].str.endswith('年度报告(修订版) ')]
df_temporary1 = df_2[-df_2['公告标题'].isin(df_21['公告标题'])]
df_temporary2 = df_temporary1[-df_temporary1['公告标题'].isin(df_22['公告标题'])]
df_temporary3 = df_temporary2[-df_temporary2['公告标题'].isin(df_23['公告标题'])]
df_temporary4 = df_temporary3[-df_temporary3['公告标题'].isin(df_24['公告标题'])]
df_final = df_2[-df_2['公告标题'].isin(df_temporary4['公告标题'])]
df_final = df_final.reset_index(drop=True)
df_sh_filter = df_final.replace('-',None)
df_sh_filter.to_excel('df_sh_filter.xlsx')
df_sh_filter = pd.read_excel('df_sh_filter.xls')
year = [f[0:4] for f in df_sh_filter['公告时间']]
df_sh_filter['year'] = year
df_sh_filter.to_excel('df_sh_filter.xlsx')
提取出两所年报下载链接的dataframe

# 下载深交所年报
import xlrd #导入上一步存的excel文件
bk1 = xlrd.open_workbook('df_sz_filter.xls')
sh = bk1.sheets()[0] # 获取所有sheet,取第1个sheet页,如果有多个sheet也可以使用sheet_by_name()方法
# 获取表中总行数
nrows = sh.nrows
print("nrows:", nrows)
# 表中第一行有标题,需要从第2行开始
for i in range(1, nrows-1):
print("下载第 %d 份年报" % i)
name = sh.cell_value(i, 2) # 读取公司名字
print('公司名称: ', name)
href_name = sh.cell_value(i, 3) # 读取链接名字
print('href_name: ', href_name)
r = requests.get(df_sz_filter['attachpath'][i],allow_redirects=True) # 下载到本地
f = open(name+href_name + "." + "pdf",'wb') # 构造完整文件路径+名称
f.write(r.content)
f.close()
r.close()
time.sleep(2)
# 下载上交所年报(命名比较不规范,所以此处下载时统一规范命名)
bk2 = xlrd.open_workbook('df_sh_filter.xls')
sh = bk2.sheets()[0]
nrows = sh.nrows
print("nrows:", nrows)
import requests
# 表中第一行有标题,需要从第2行开始
for i in range(1, nrows-1):
print("下载第 %d 份年报" % i)
name = sh.cell_value(i, 3) # 读取公司名字
print('公司名称: ', name)
year = sh.cell_value(i, 7) # 读取链接名字
year = str(year)
print('公告年度: ', year)
r = requests.get(df_sh_filter['href'][i],allow_redirects=True) # 下载到本地
time.sleep(2)
f = open(name + year + '年度报告' + "." + "pdf",'wb') # 下载时候统一规范名称
f.write(r.content)
f.close()
r.close()
time.sleep(2)
年报下载情况截图(上交所为例)

将年报按公司整理(上交所为例)
#提取每股净收益
def get_profit(pdf):
text = getText(pdf)
p = re.compile('(?<=\\n)\D、\s*\D*?主要\D*?指标\D*?\s*(?=\\n)(.*?)稀释每股',re.DOTALL)
profit = p.search(text).group(0)
return(profit)
def profit_data_line(pdf):
profit = get_profit(pdf)
subp = "([0-9,.%\- ]*?)\n"
psub = "%s%s%s%s" % (subp,subp,subp,subp)
p =re.compile("(?<=\\n)基本每股收益(\D*?\n)+%s" % psub)#定义每股收益所在行的内容
lines_profit = p.search(profit)
lines_profit = lines_profit[0]
return(lines_profit)
# 以下分别对上交所和深交所的年报文件夹运行
import os
filenames = os.listdir() #把代码所在文件夹的所有文件和文件名查找出来
pdf_list = [f for f in filenames if f.endswith('.pdf')]
df = pd.DataFrame(columns = ["name", "year", "pdf"])
df["name"] = [f[0:4] for f in pdf_list]
years = [f[4:8] for f in pdf_list]
df['year'] = years
df['pdf'] = pdf_list
df = df.sort_values(by='year', ascending=False)
sale = []
for pdf in df['pdf']:
i=0
df = pd.DataFrame()
df1 = pd.DataFrame()
#year = pdf[4:9]
doc = fitz.open(pdf) #打开pdf
text = [page.getText() for page in doc]
text = ''.join(text)
p_re = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
revenue = p_re.search(text).group(1)
revenue = revenue.replace(',','') #把revenue里的逗号去掉
sale.append(revenue)
profit_gain = profit_data_line(pdf)
profit_gain = profit_gain.split("\n")
profit_gain = profit_gain[1]
profit.append(profit_gain)
df.insert(i,,sale)
df1.insert(i,,profit)
df_sale = df_sale.join(df, how='outer')
df_profit = df_profit.join(df1,how='outer')
index = ['2021','2020','2019','2018','2017',\
'2016','2015','2014','2013','2012']
df_sale.index = index
df_sale.to_excel('/Users/xieqinyan/Desktop/金融数据获取与处理/上交所revenue.xlsx')
df_profit.index = index
df_profit.to_excel('/Users/xieqinyan/Desktop/金融数据获取与处理/上交所pe.xlsx')
运行结果(以上交所为例)


# 上交所和深交所分开提取
df_place = pd.DataFrame()
df_web = pd.DataFrame()
filenames = os.listdir() #把代码所在文件夹的所有文件和文件名查找出来
pdf_list = [f for f in filenames if f.endswith('.pdf')]
place_sh =[]
web = []
for pdf in filenames:
i=0
df = pd.DataFrame()
df1 = pd.DataFrame()
doc = fitz.open(pdf) #打开pdf
text = [page.getText() for page in doc]
text = ''.join(text)
p_place = re.compile('(?<=\n)\w*办公地址:?\s?\n?(.*?)\s?(?=\n)',re.DOTALL)
place = p_place.search(text).group(1)
place_sh.append(place)
p_web = re.compile('(?<=\n)公司\w*网址\s*(.*?)\s*(?=\n)')
href = p_web.search(text).group(1)
web.append(href)
df.insert(i,'办公地址', place_sh)#以列为单位加入表格
df1.insert(i,'网址', web)
df_site = df_site.join(df, how='outer')
df_web = df_web.join(df1, how='outer')
df_web = pd.DataFrame(df_web)
df_web.to_excel('web_sh.xlsx')
df_place = pd.DataFrame(df_place)
df_place.to_excel('上交所site.xlsx')
运行结果

遇到的问题:有一家公司没有网址,故手动添加为:公司网址 无
# 合并每股收益
pe1 = pd.read_excel('深交所pe.xlsx', index_col='Unnamed: 0')
pe2 = pd.read_excel('上交所pe1.xlsx', index_col='Unnamed: 0')
pe = pe1.join(pe2)
pe.to_csv('每股收益.csv')
# 合并营业收入
rev1 = pd.read_excel('深交所revenue.xlsx', index_col='Unnamed: 0')
rev2 = pd.read_excel('上交所revenue.xlsx', index_col='Unnamed: 0')
rev = rev1.join(rev2)
rev.to_csv('营业收入.csv')
rev.to_excel('营业收入.xlsx')
# 合并办公地址
p1 = pd.read_excel('深交所site.xlsx', index_col='Unnamed: 0')
p1['股票简称'] = df_sz['公司名称'].values
p1['股票代码'] = df_sz['公司代码'].values
p2 = pd.read_excel('上交所site.xlsx', index_col='Unnamed: 0')
p2['股票简称'] = df_sh['公司名称'].values
p2['股票代码'] = df_sh['公司代码'].values
place = pd.concat([p1,p2])
place.index = range(23)
place.to_csv('公司基本信息.csv')
# 合并公司网址
w1 = pd.read_excel('web_sz.xlsx', index_col='Unnamed: 0')
w1['股票简称'] = df_sz['公司名称'].values
w1['股票代码'] = df_sz['公司代码'].values
w2 = pd.read_excel('web_sh.xlsx', index_col='Unnamed: 0')
w2['股票简称'] = df_sh['公司名称'].values
w2['股票代码'] = df_sh['公司代码'].values
web = pd.concat([w1,w2])
web.to_csv('公司网址.csv')
place = pd.read_csv('公司基本信息.csv', index_col='股票代码')
del place['Unnamed: 0']
del place['股票简称']
web.index = web['股票代码']
info = pd.DataFrame()
info = pd.concat([web,place],axis=1)
info.to_csv('公司信息.csv')
info = pd.read_excel('公司信息.xlsx')
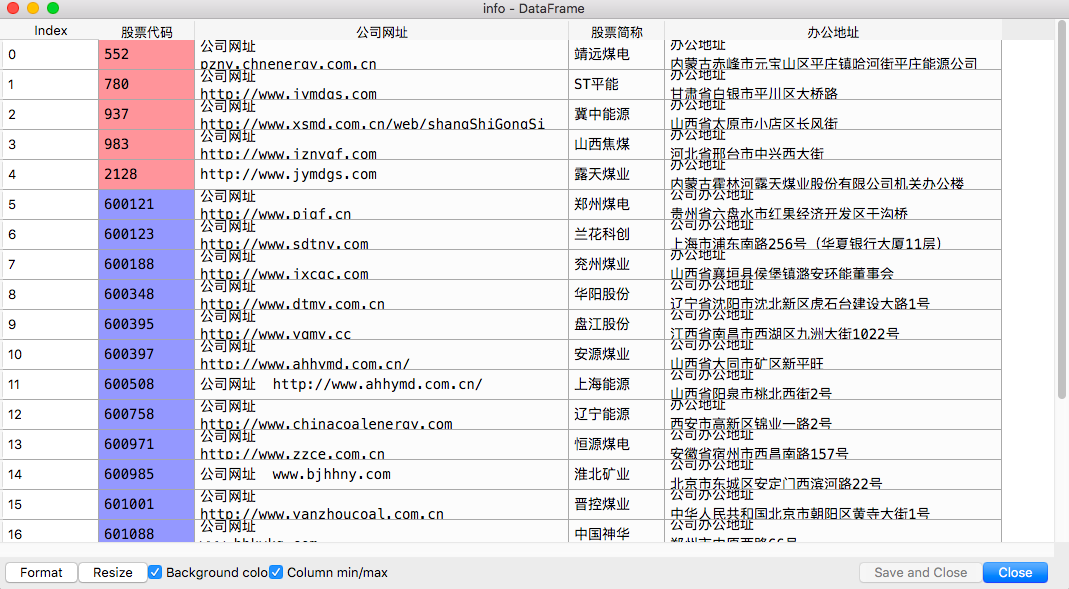
最终提取的信息截图
营业收入:

每股收益:

公司信息:
# 选取年平均收入最高的10家公司
rev = pd.read_excel('/Users/xieqinyan/Desktop/金融数据获取与处理/营业收入.xlsx')
rev_mean = rev.mean()
rev_10 = rev_mean.sort_values().iloc[-10:]
com1 = pd.Series(rev_10.index) # 得到10家公司的名称
com1 = com1.to_list()
com1
# 提取对应公司的营业收入、基本每股收益,存在本地
rev_10 = rev.loc[:,com1]
pe_10 = pe.loc[:,com1]
rev_10.to_excel('画图1.xlsx')
pe_10.to_excel('画图2.xlsx')
同一年10家对比:
import matplotlib.pyplot as plt
import matplotlib
import csv
from matplotlib.pyplot import MultipleLocator
import matplotlib.font_manager as fm
import matplotlib
rev_10 = pd.read_excel('/Users/xieqinyan/Desktop/金融数据获取与处理/画图1.xlsx', index_col='Unnamed: 0')
# 定义函数,缩小数字分位,使作图更美观
def change_type(list_x):
list_w=[]
for i in range(len(list_x)):
x = []
for j in range(len(list_x[1])):
num = list_x[i][j]
num = float(num)
num = num / 10**8 # 将数值缩小为亿分之一,便于在后续图标上展示
num = round(num,2)# 保留两位小数
x.append(num)
list_w.append(x)
return(list_w)
# 得到每一年的公司营业收入。每一年的数据都转化为list
list_row = rev_10.values.tolist()
list_row_1 = change_type(list_row)
list_row_1
name_list = ['2021','2020',"2019","2018","2017","2016","2015","2014","2013",'2012']
list_name_1 = ['601001','000983','600348','000937','601699','601666','600985','601101','000780','600971']
# 设置字体
plt.rcParams['font.sans-serif']=['/System/Library/Fonts/Hiragino Sans GB.ttc']
plt.rcParams['axes.unicode_minus']=False
fname = "/System/Library/Fonts/Hiragino Sans GB.ttc"
zhfont1 = fm.FontProperties(fname=fname)
# Colors是一些自选颜色列表
Colors=('#7D7DFF','#CEFFCE','#28FF28','#007500','#FFFF93',\
'#8C8C00','#FFB5B5','#FF0000','#CE0000','#750000')
# 每年的公司对比图
def y_ticks(list_row,name_list):
num_list_1 = list_row
rects = plt.barh(range(len(list_row)),num_list_1,color=Colors)
N = 10
index = np.arange(N)
plt.yticks(index,list_name_1,fontproperties = zhfont1)
plt.title(name_list+" of Revenue Comparison",fontproperties = zhfont1)
plt.xlabel("Revunue(Billion)",fontproperties = zhfont1)
plt.ylabel("Company Name",fontproperties = zhfont1)
for rect in rects:
w=rect.get_width()
plt.text(w,rect.get_y()+rect.get_height()/2,w,size =10,ha='left',va='center')
plt.savefig(name_list +".png",dpi = 600)
plt.show()
for i in range(len(list_row)):
y_ticks(list_row_1[i], name_list[i])
各年度不同公司营业收入对比
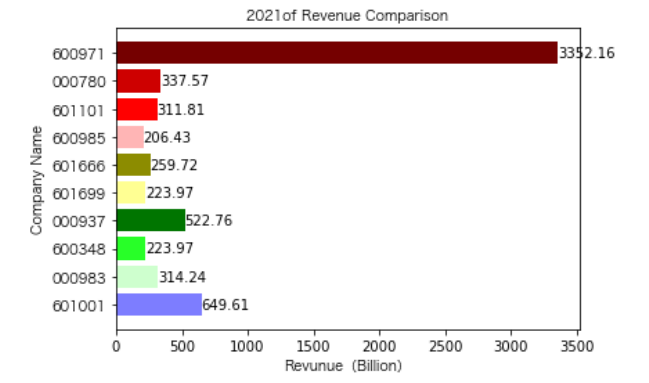
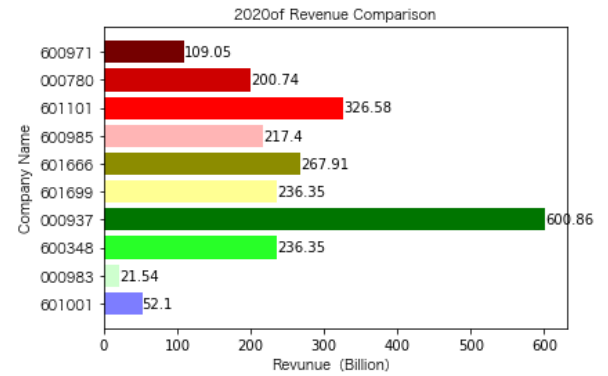
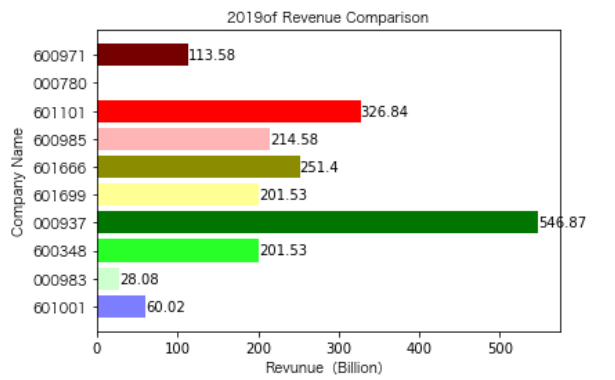
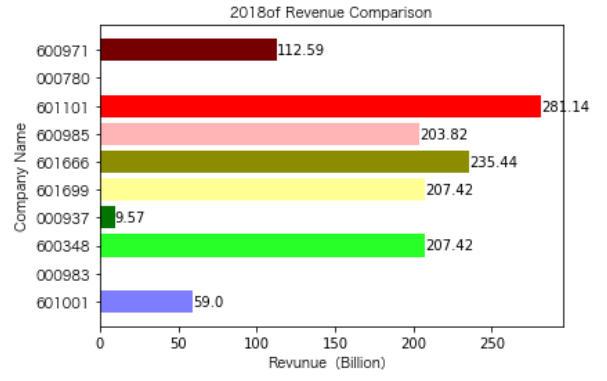
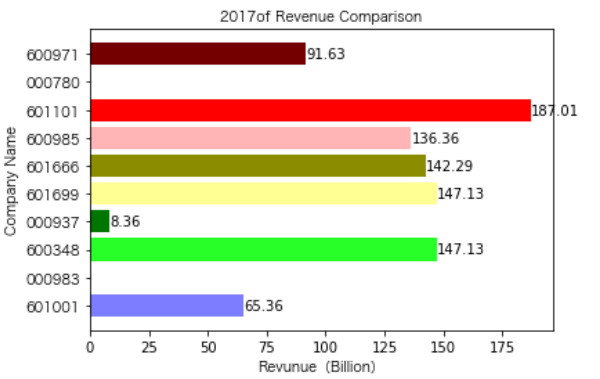
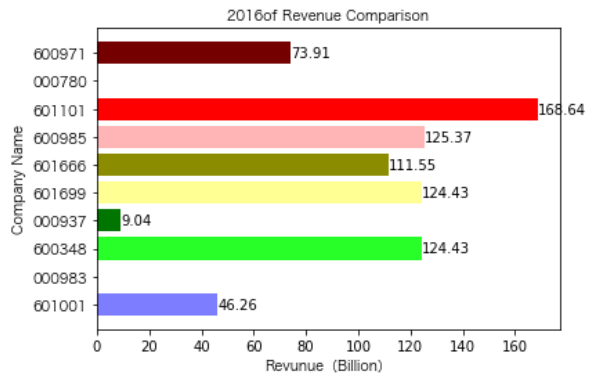
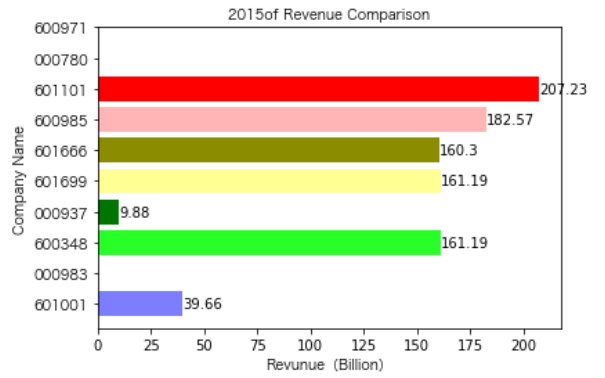
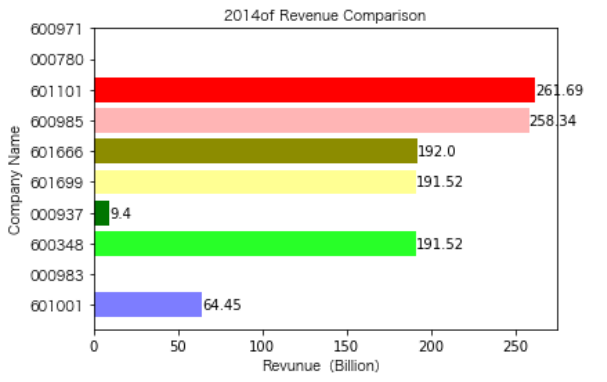
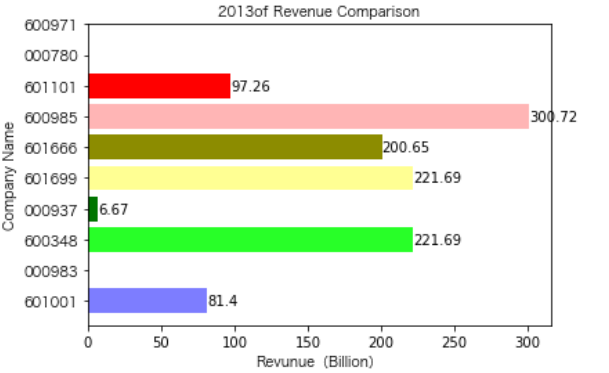
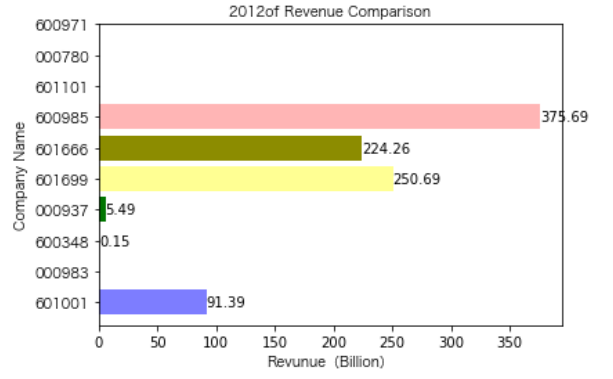
同一公司10年对比:
# 得到每家公司10年的数据,并转化为list
name_columns = rev_10.columns
list_columns = []
for i in name_columns:
d = rev_10[i].values.tolist()
list_columns.append(d)
list_columns = change_type(list_columns)
def x_ticks(list_columns,list_name):
num_list = list_columns
rects = plt.bar(range(len(list_columns)),num_list,color=Colors,width = 1,tick_label=name_list)
plt.title(list_name+"在2012-2021的营业收入变化趋势",fontproperties = zhfont1)
plt.xlabel("年份",fontproperties = zhfont1)
plt.ylabel("营业收入(百万元)",fontproperties = zhfont1)
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), size=10, ha="center", va="bottom")
plt.savefig(list_name +".png",dpi = 600)
plt.show()
for i in range(len(list_columns)):
x_ticks(list_columns[i], list_name_1[i])
各公司营业收入对比
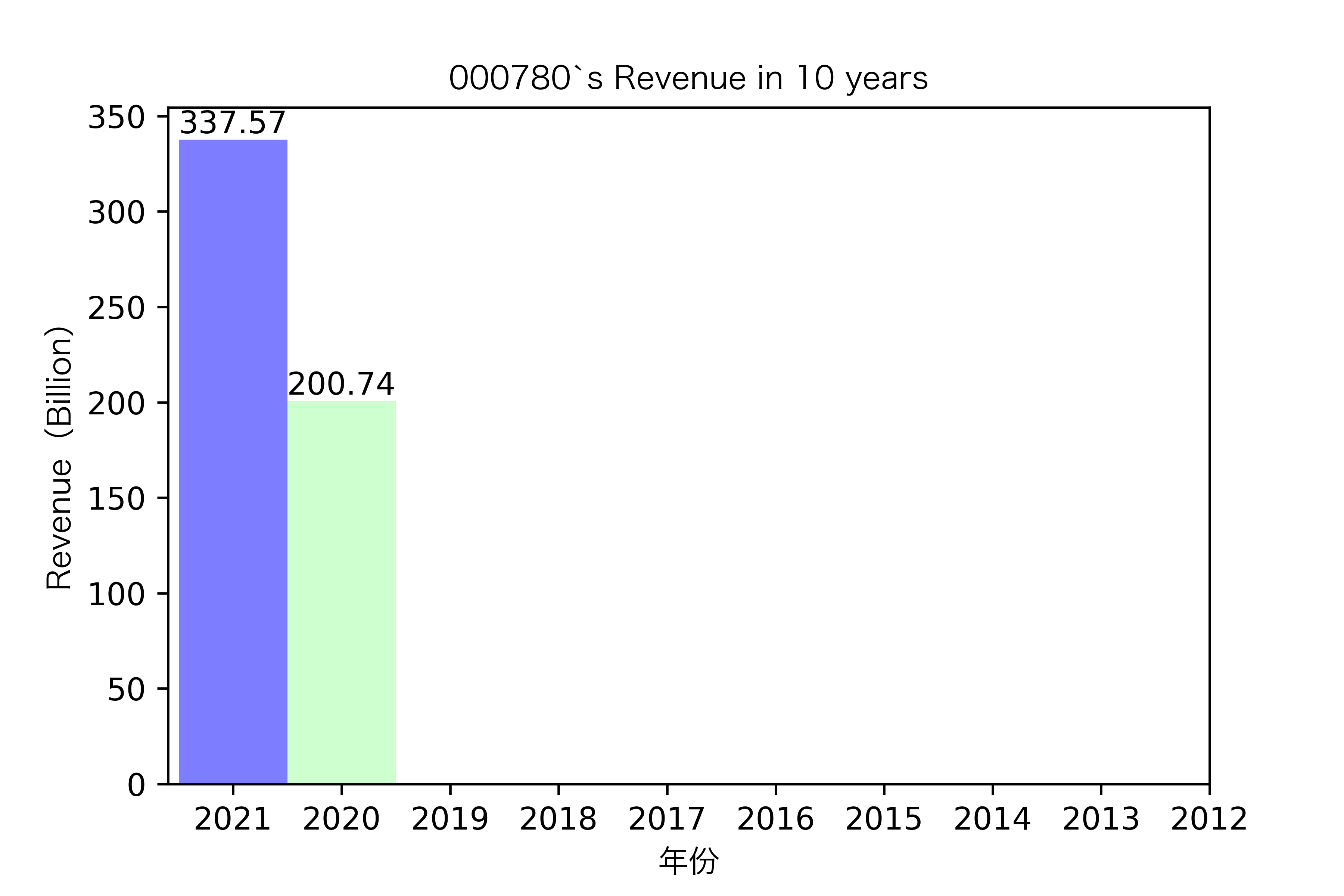
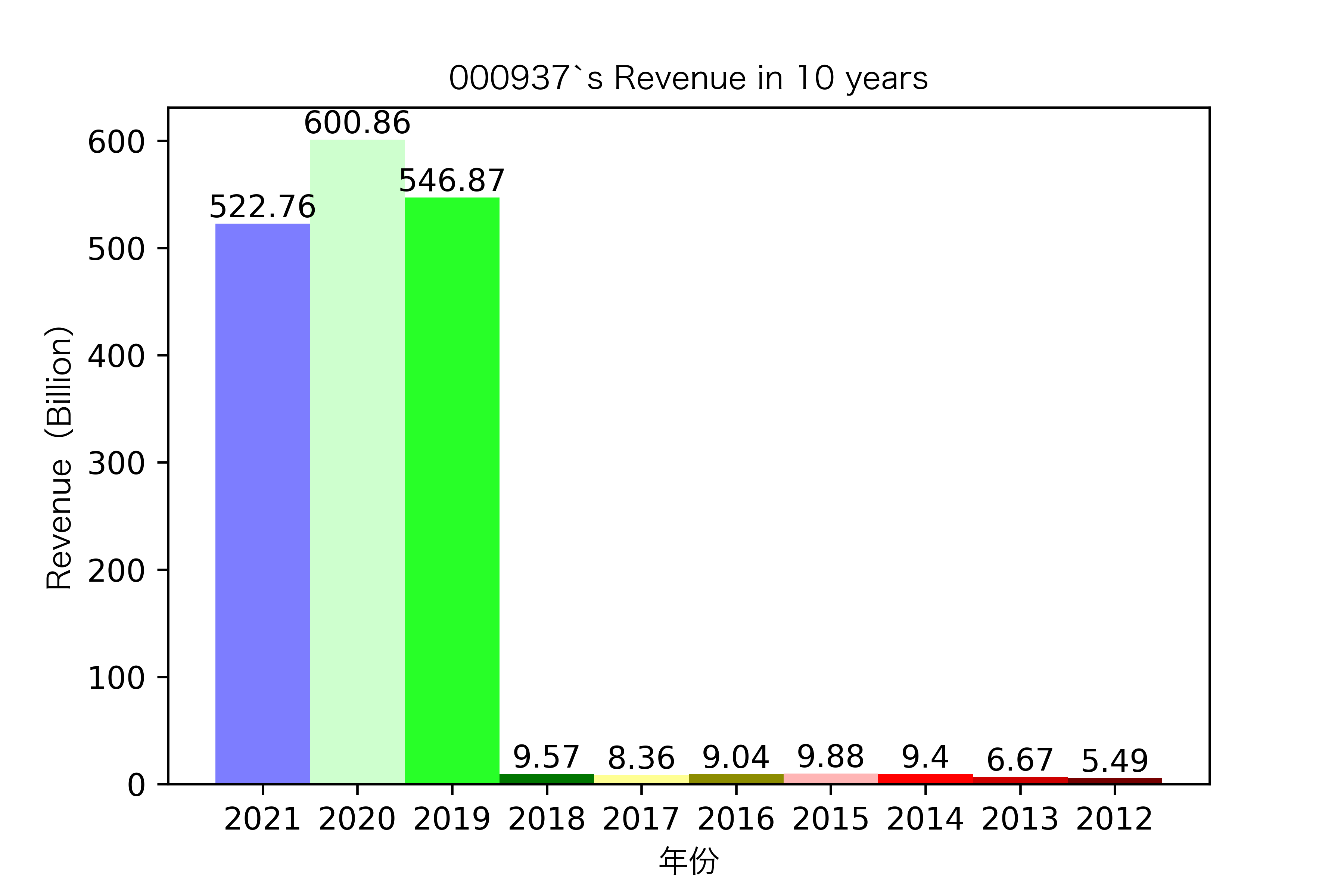
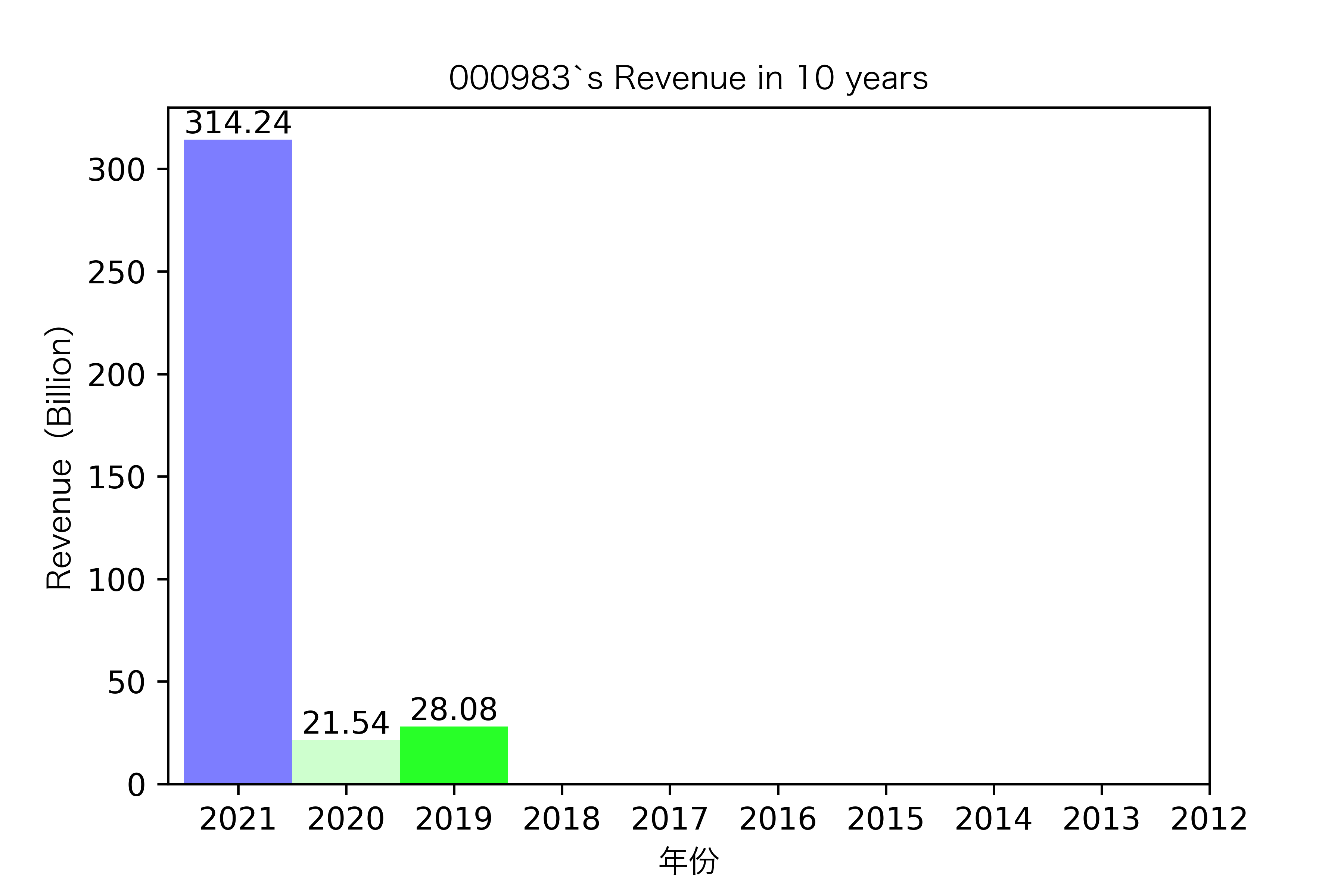
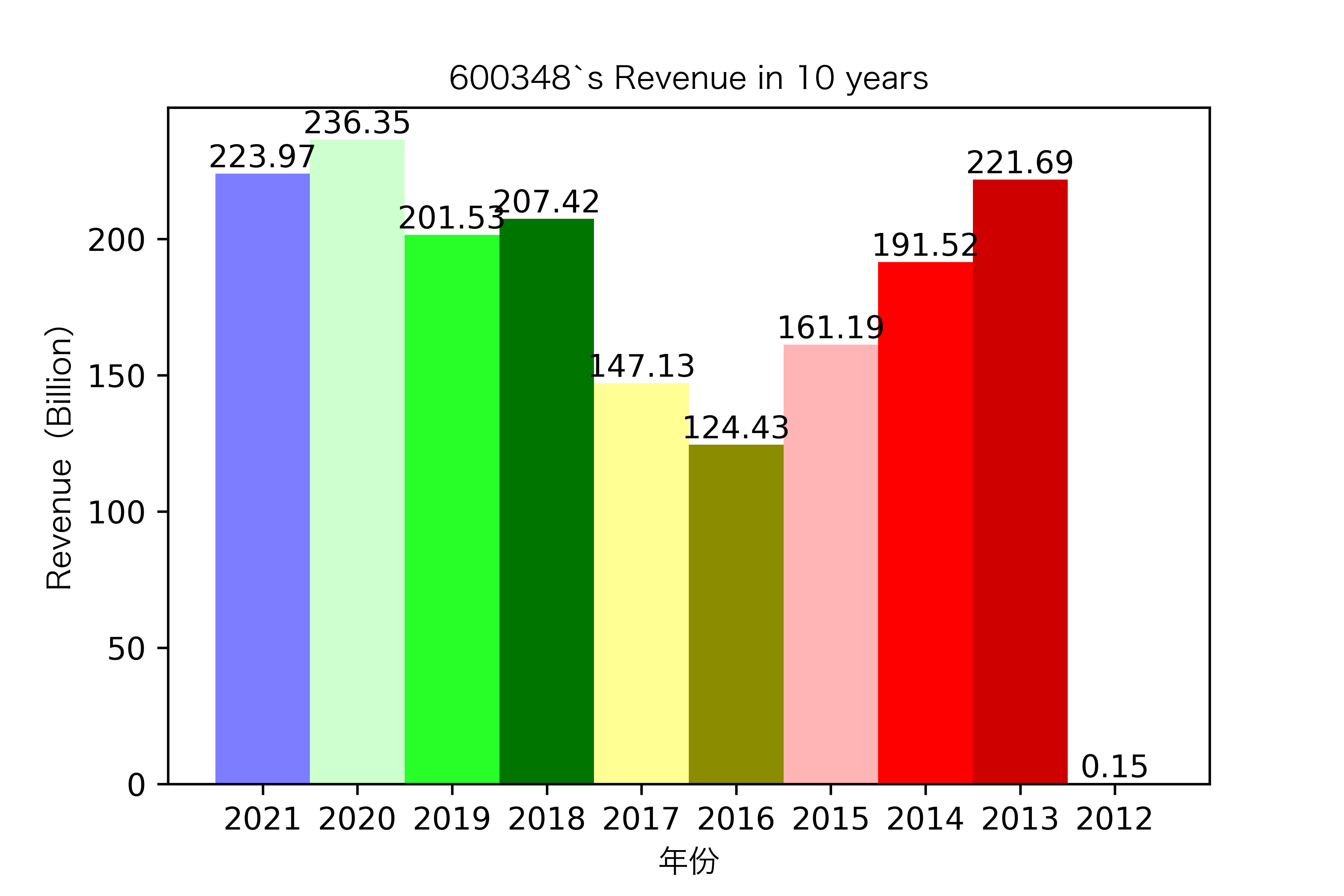
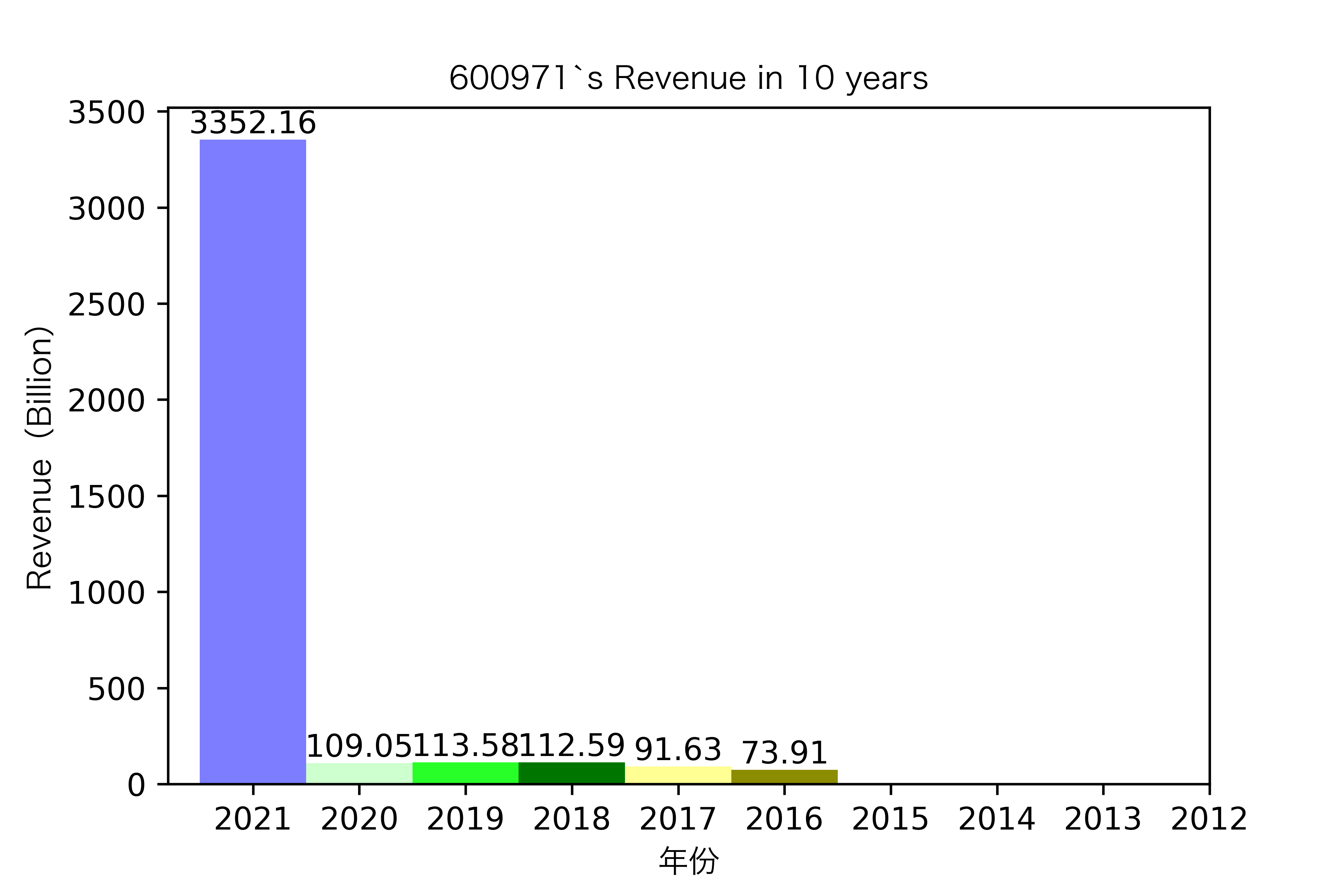
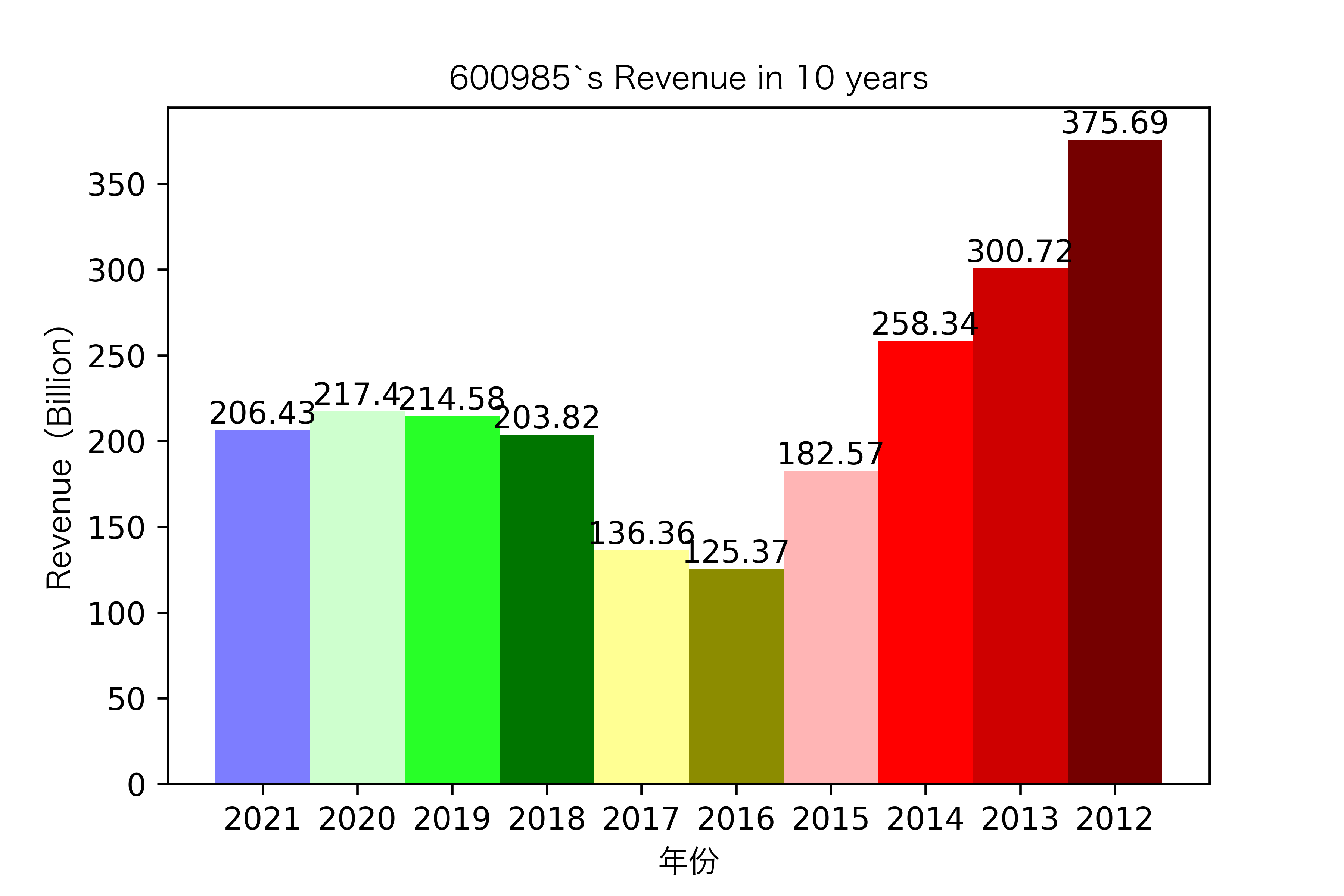
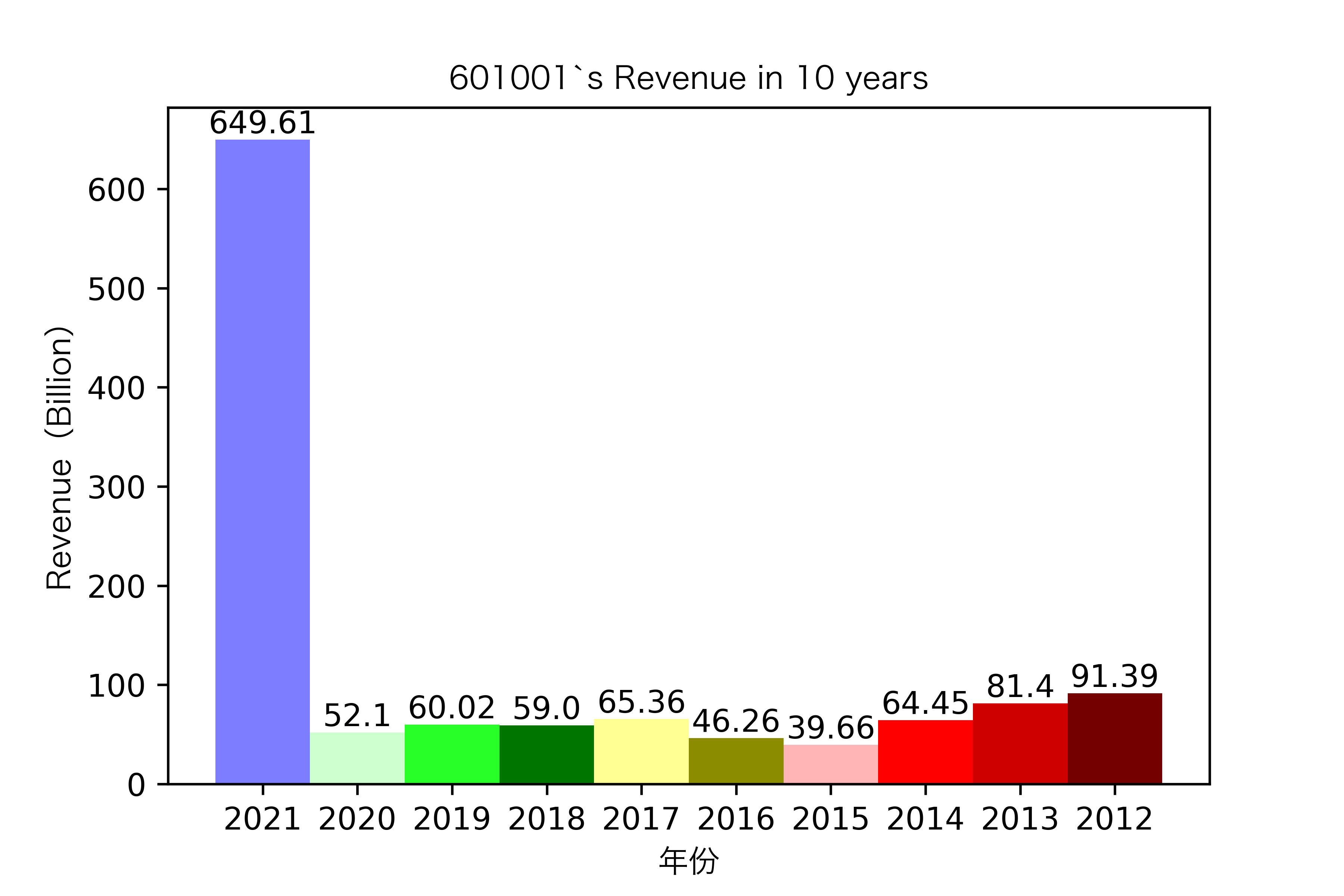
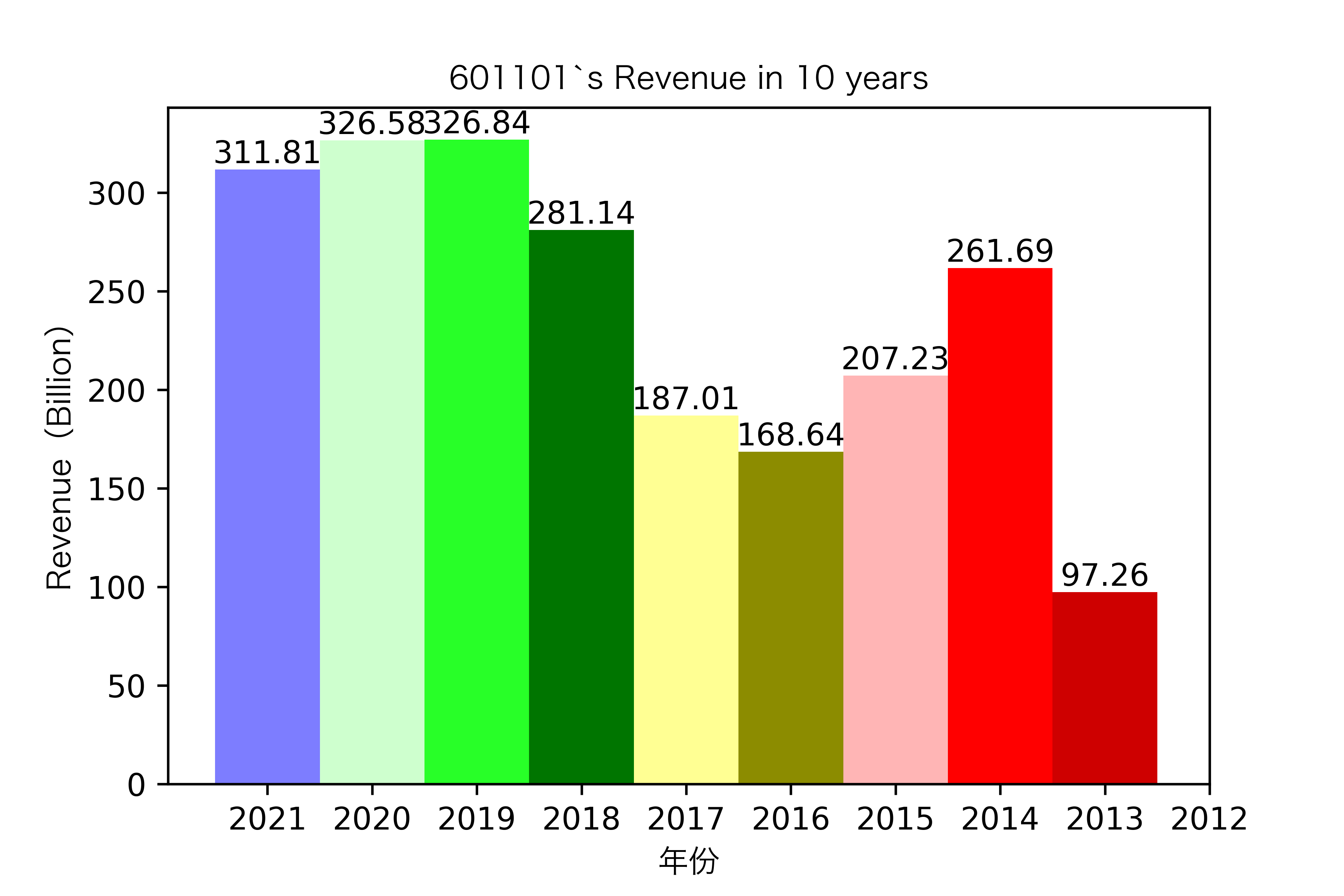
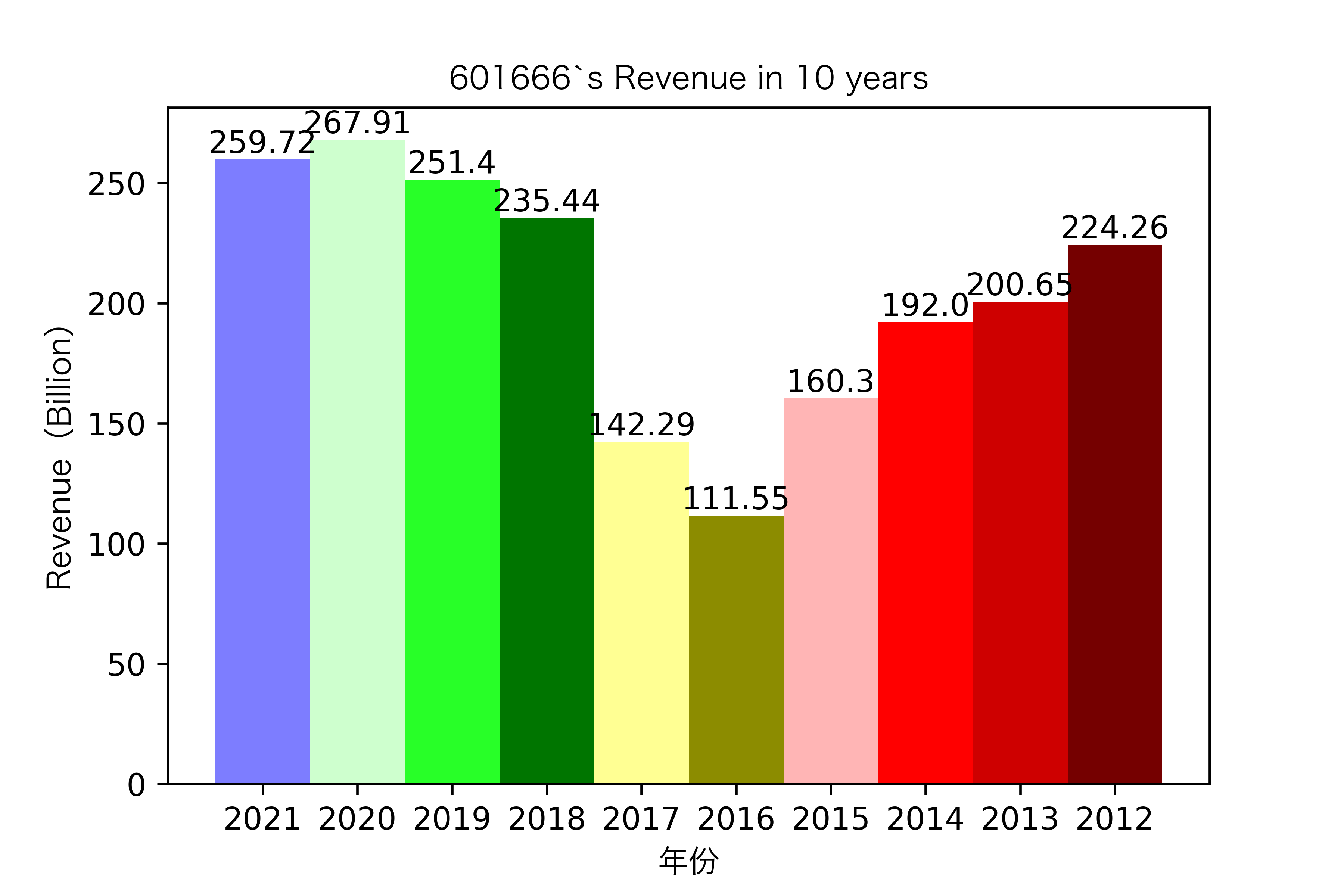
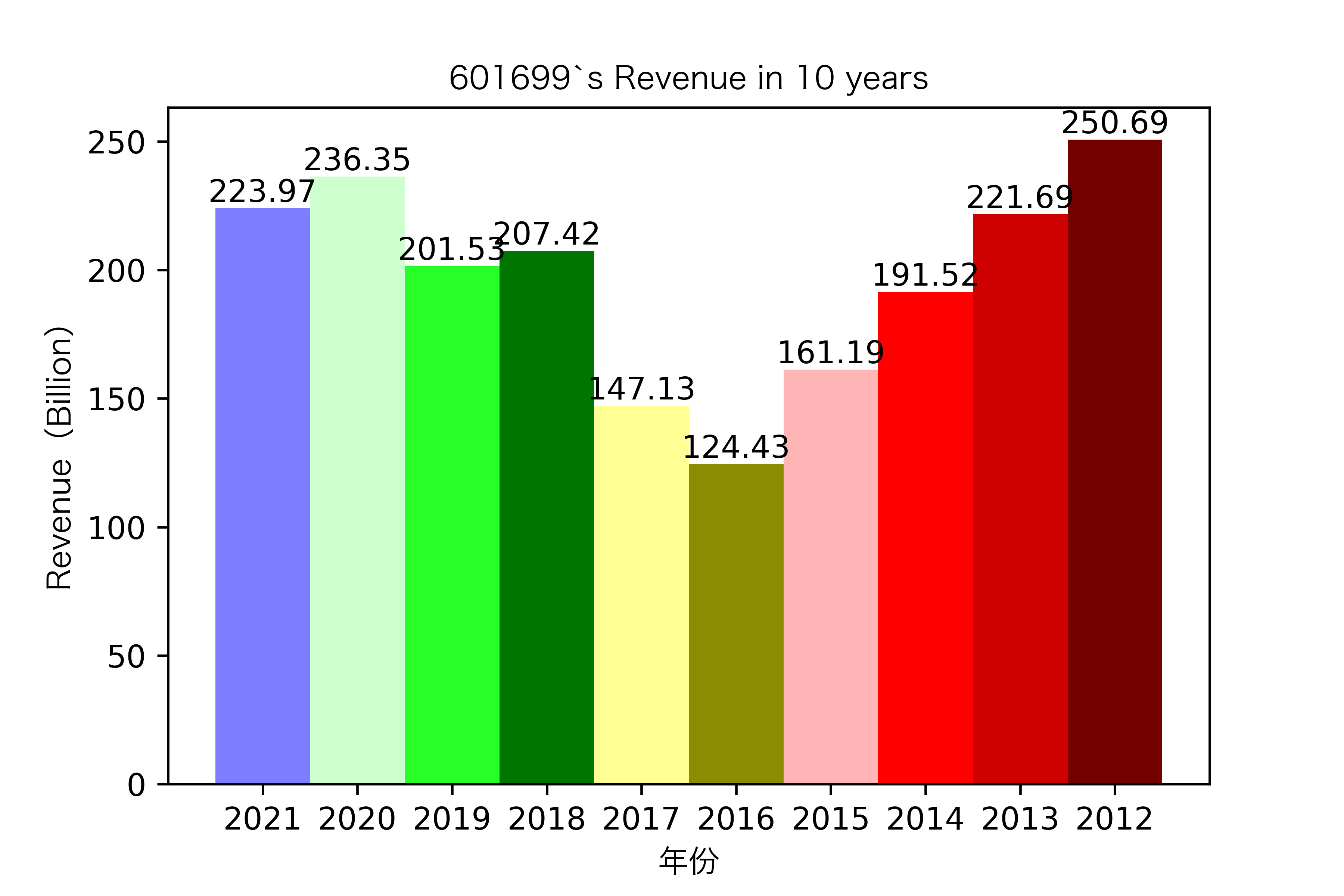
同一年10家对比:
# 每一年的数据为一个list
pe_10 = pd.read_excel('/Users/xieqinyan/Desktop/金融数据获取与处理/画图2.xlsx', index_col='Unnamed: 0')
list_row = pe_10.values.tolist()
list_row
for i in range(len(list_row)):
y_ticks(list_row[i], name_list[i])
def y_ticks(list_row,name_list):
num_list_1 = list_row
rects = plt.barh(range(len(list_row)),num_list_1,color=Colors)
N = 10
index = np.arange(N)
plt.yticks(index,list_name_1,fontproperties = zhfont1)
plt.title(name_list+"of PE Comparison",fontproperties = zhfont1)
plt.xlabel("PE",fontproperties = zhfont1)
plt.ylabel("Company Code",fontproperties = zhfont1)
for rect in rects:
w=rect.get_width()
plt.text(w,rect.get_y()+rect.get_height()/2,w,size =10,ha='left',va='center')
plt.savefig(name_list +".png",dpi = 600)
plt.show()
for i in range(len(list_row)):
y_ticks(list_row[i], name_list[i])
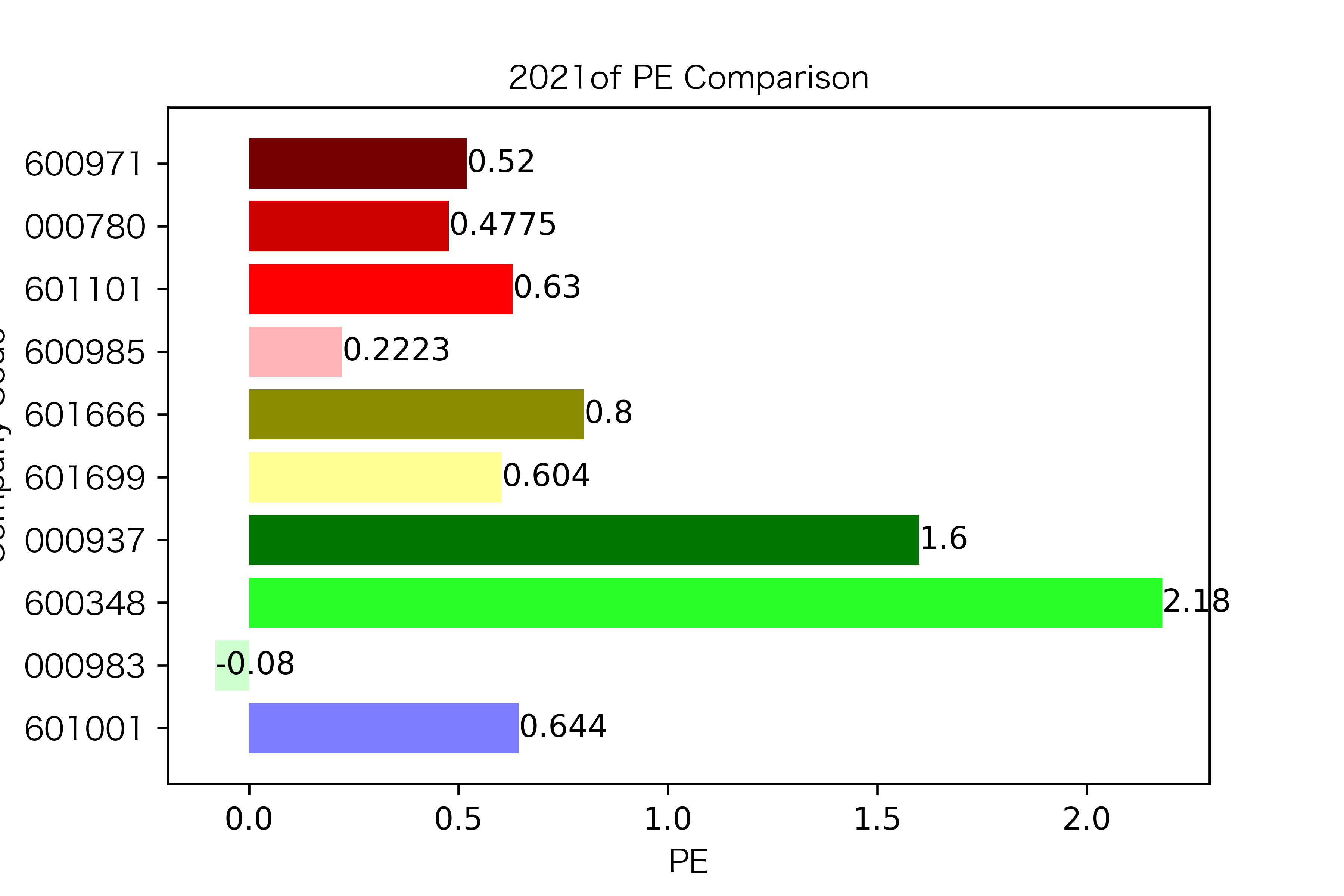
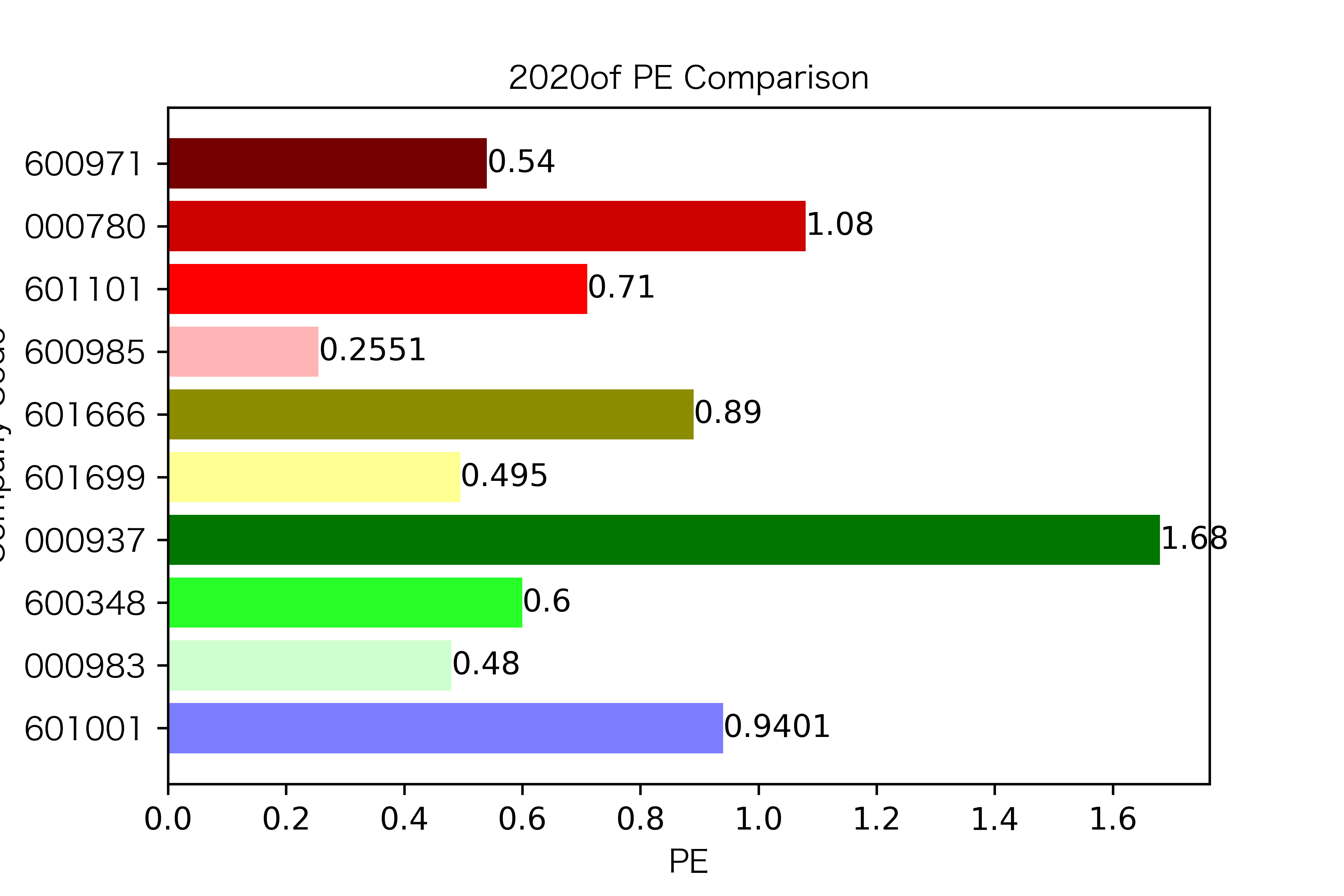
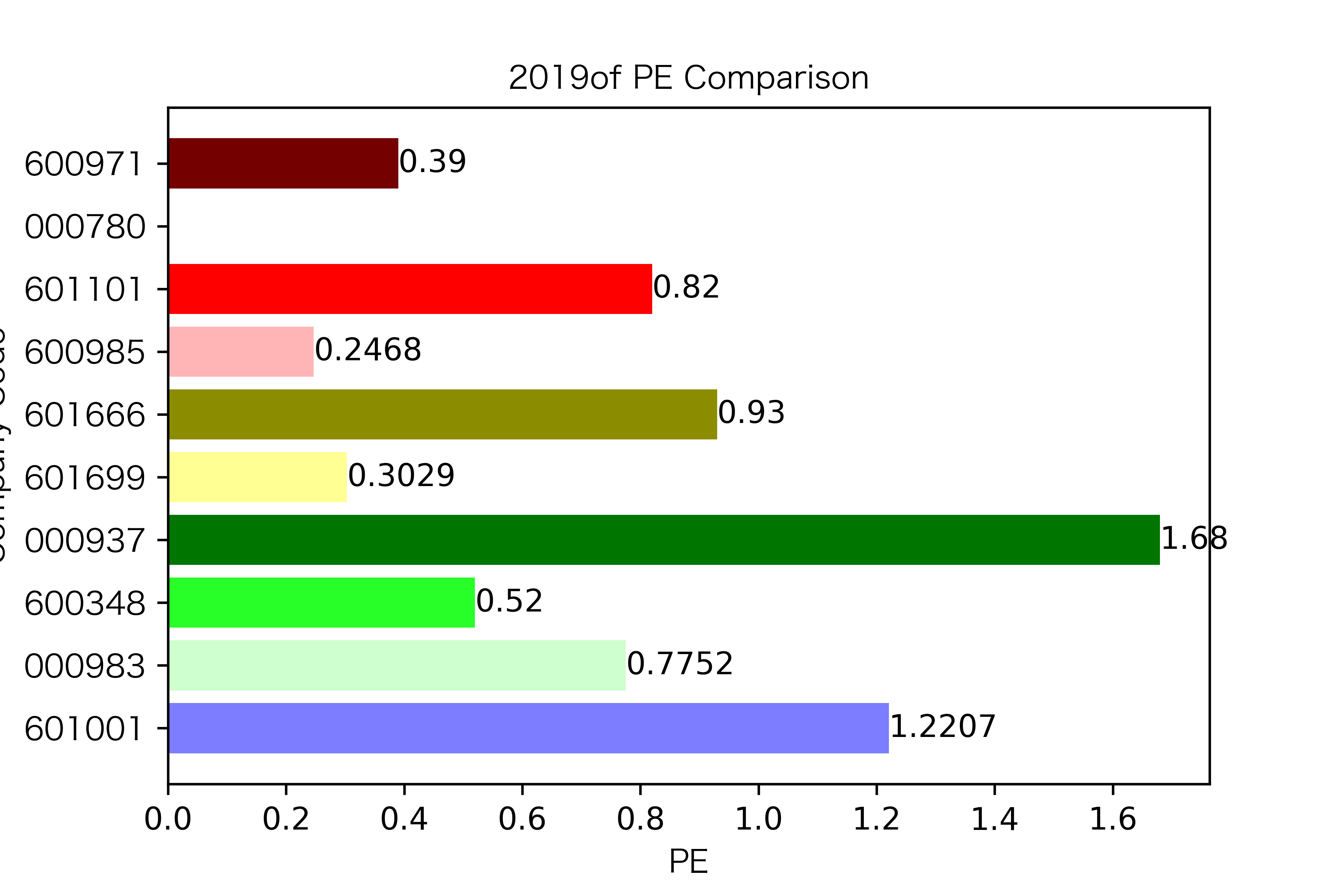
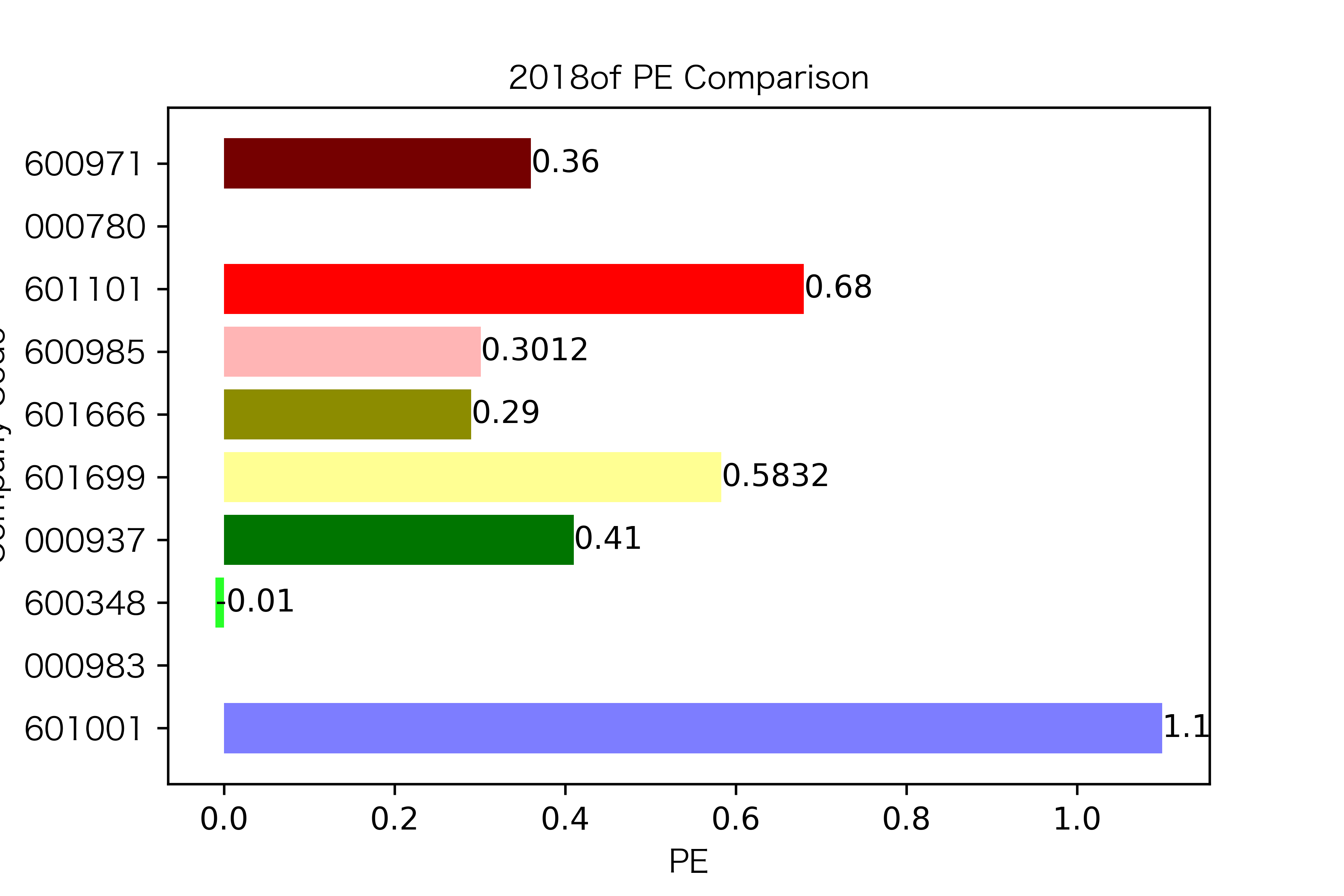
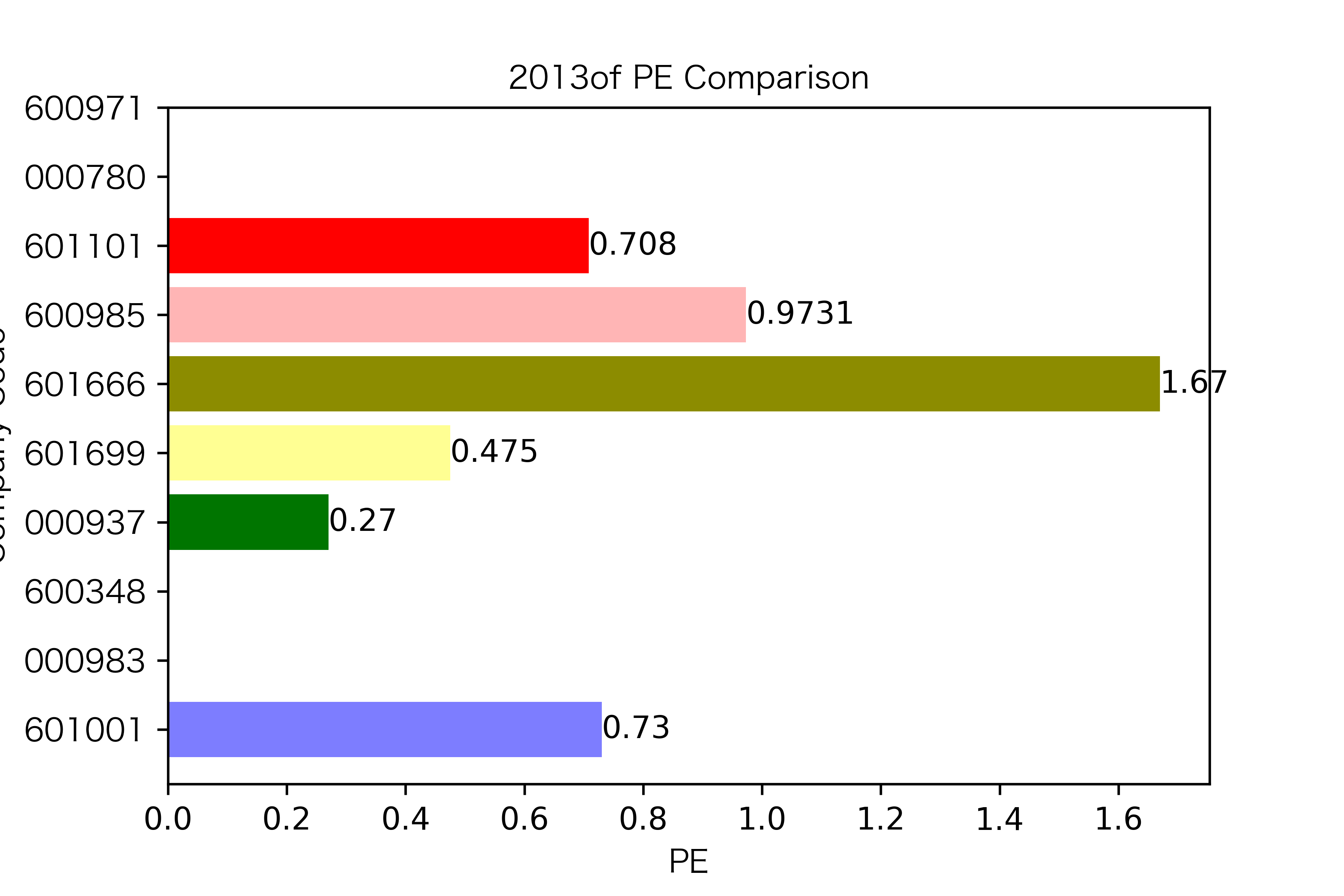
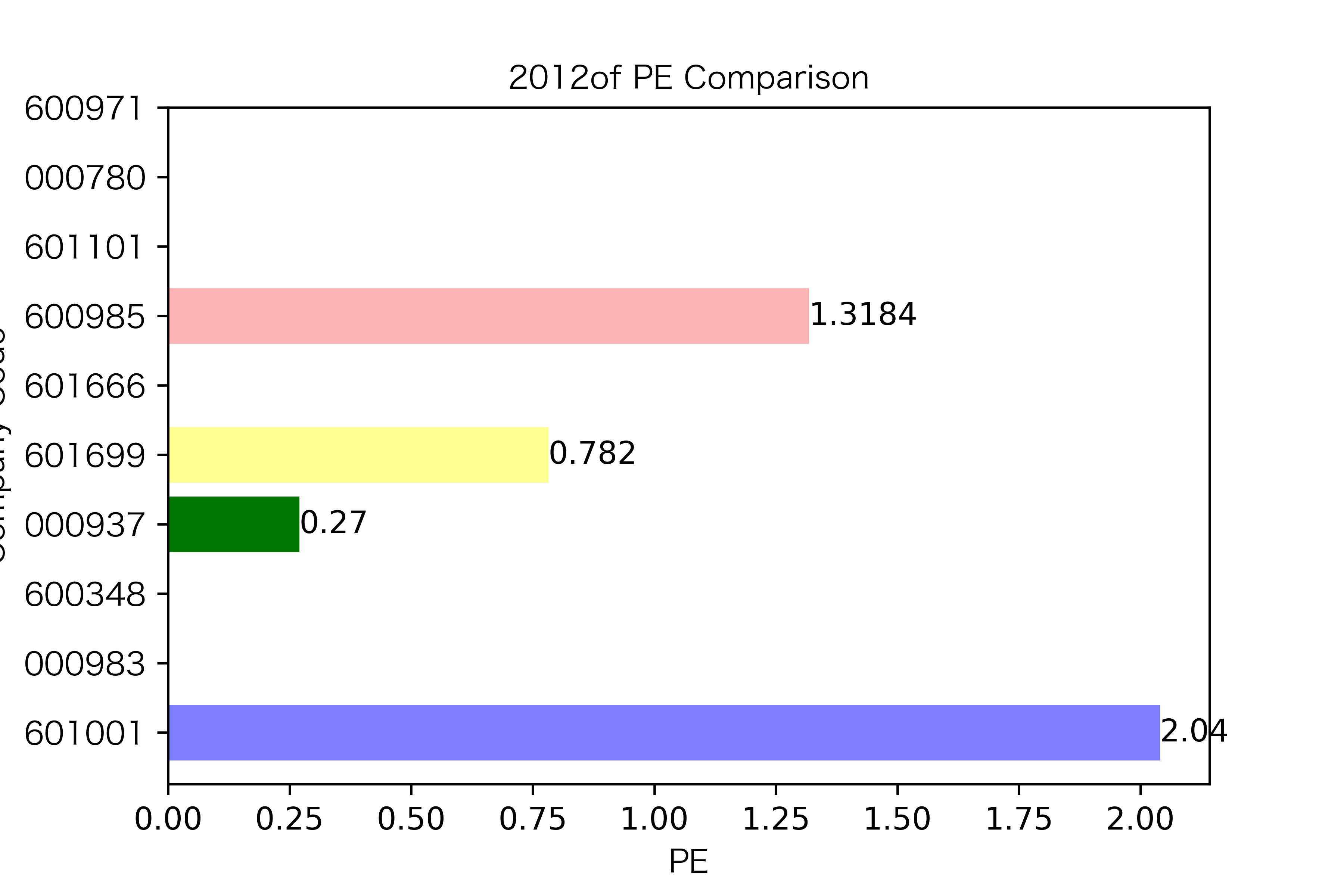
各年度不同公司每股收益对比
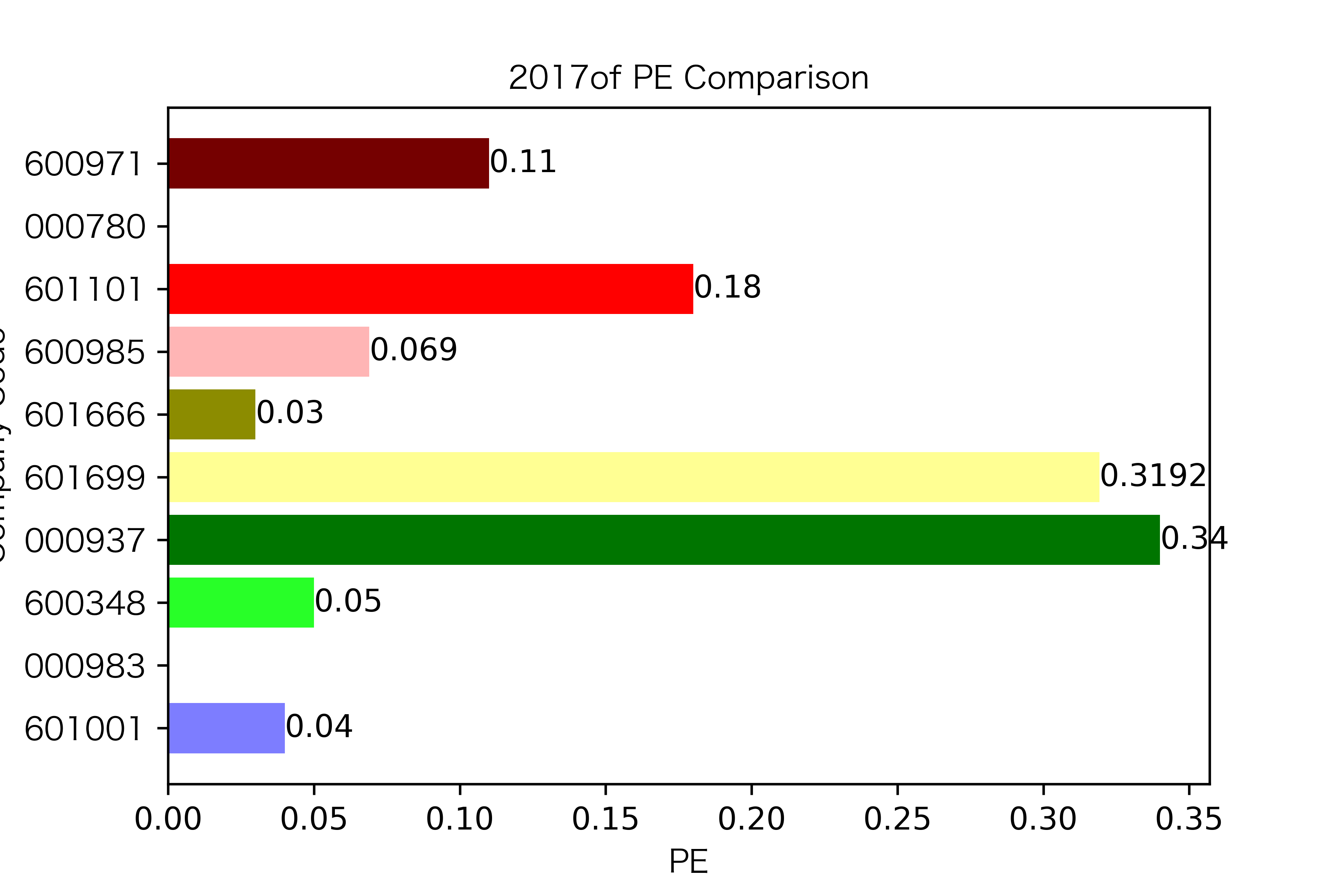
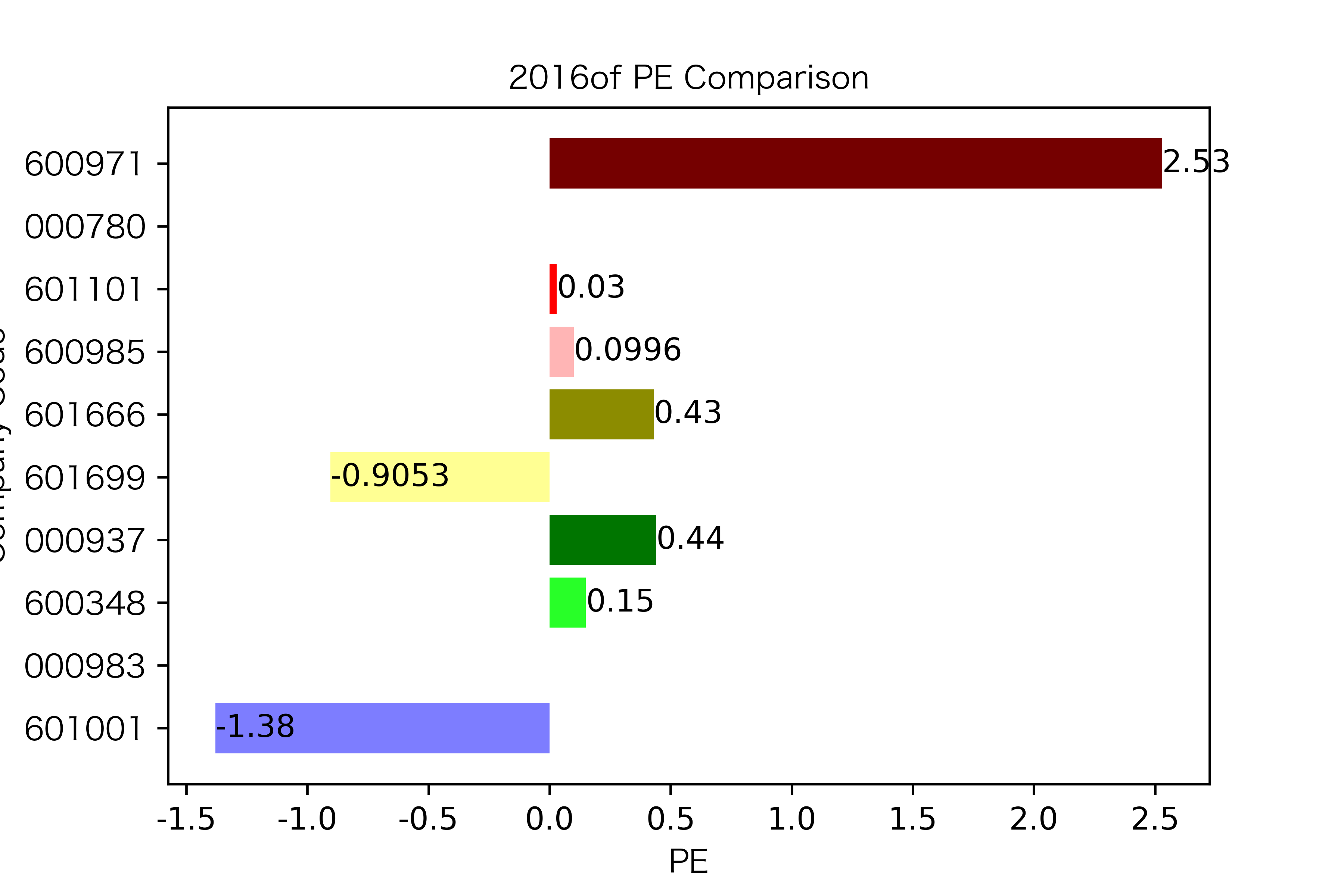
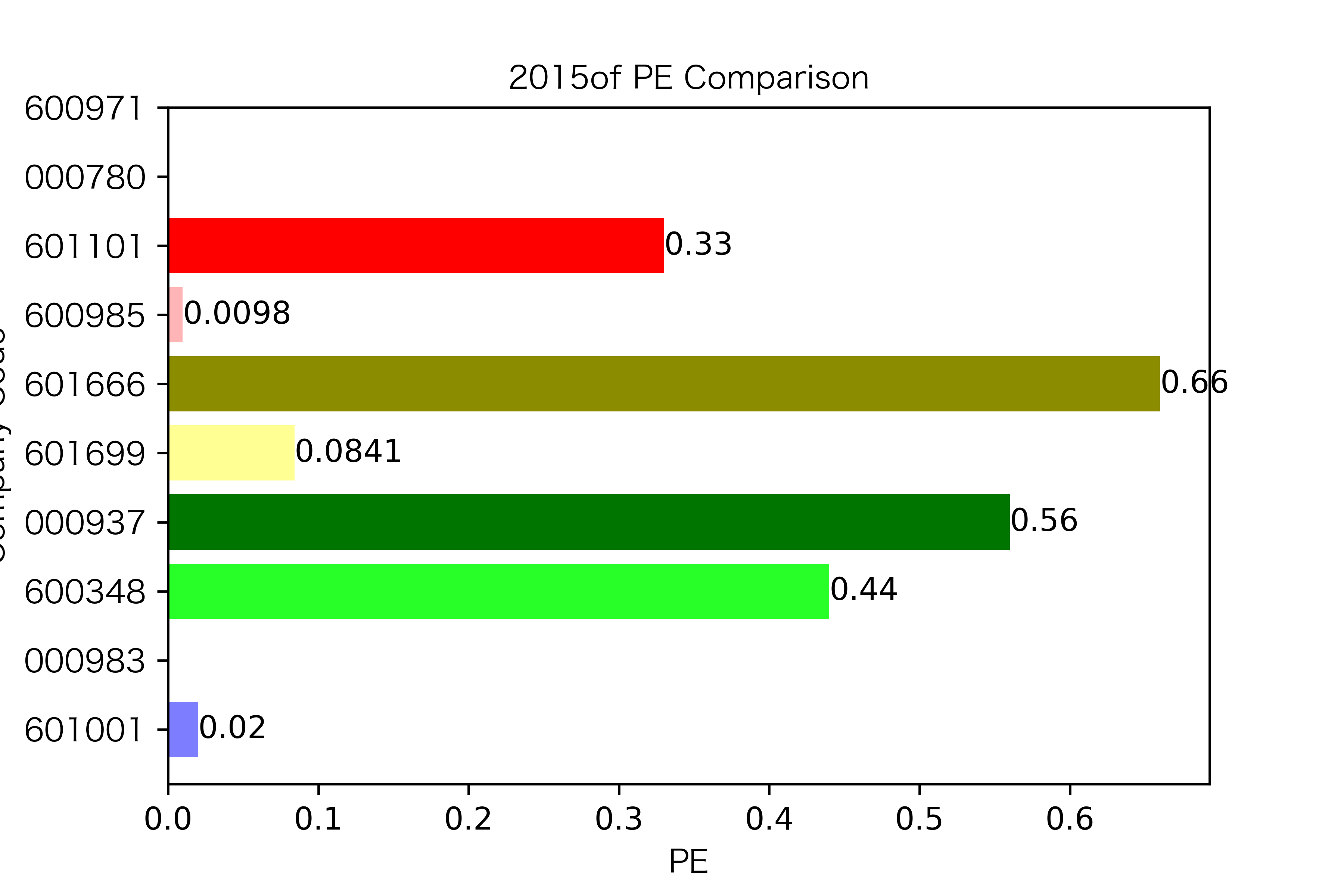
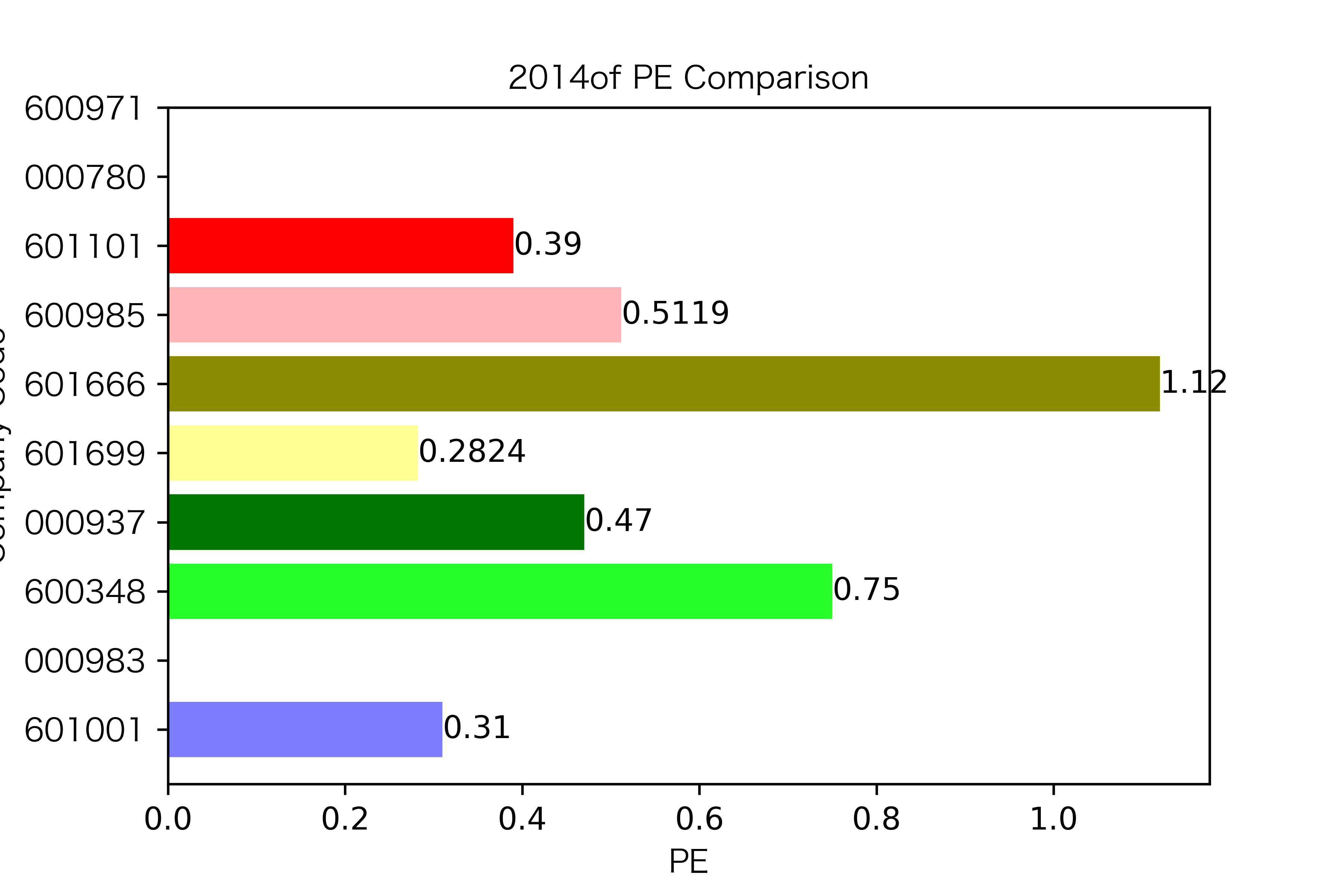
同一公司10年对比:
# 每个list为该公司10年的数据
name_columns =pe_10.columns
list_columns = []
for i in name_columns:
d = pe_10[i].values.tolist()
list_columns.append(d)
list_columns
def x_ticks(list_columns,list_name):
num_list = list_columns
rects = plt.bar(range(len(list_columns)),num_list,color=Colors,width = 1,tick_label=name_list)
plt.title(list_name+"`s PE in 10 years",fontproperties = zhfont1)
plt.xlabel("Year",fontproperties = zhfont1)
plt.ylabel("PE",fontproperties = zhfont1)
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height, str(height), size=10, ha="center", va="bottom")
plt.savefig(list_name +"每股收益.png",dpi = 600)
plt.show()
for i in range(len(list_columns)):
x_ticks(list_columns[i], list_name_1[i])
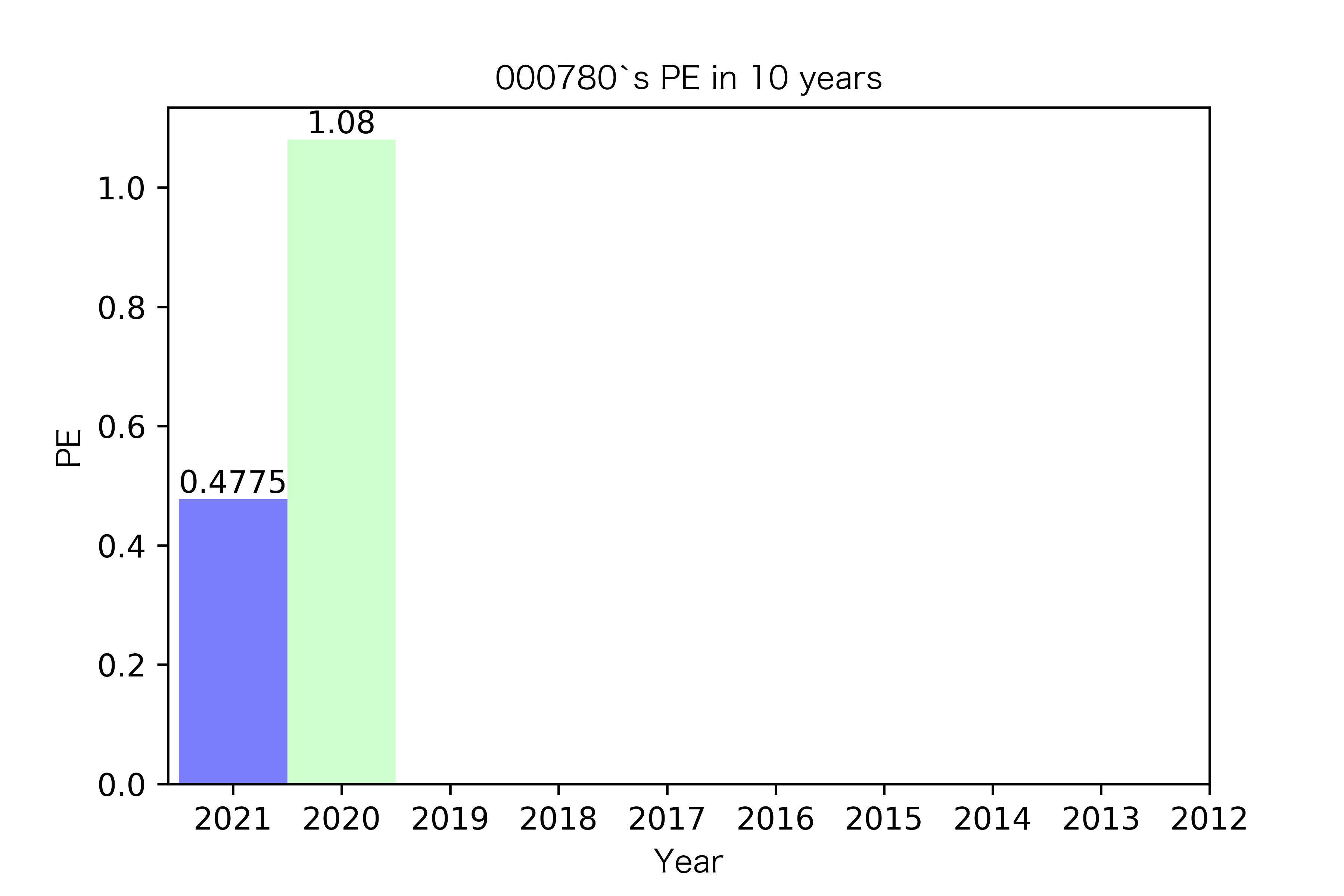
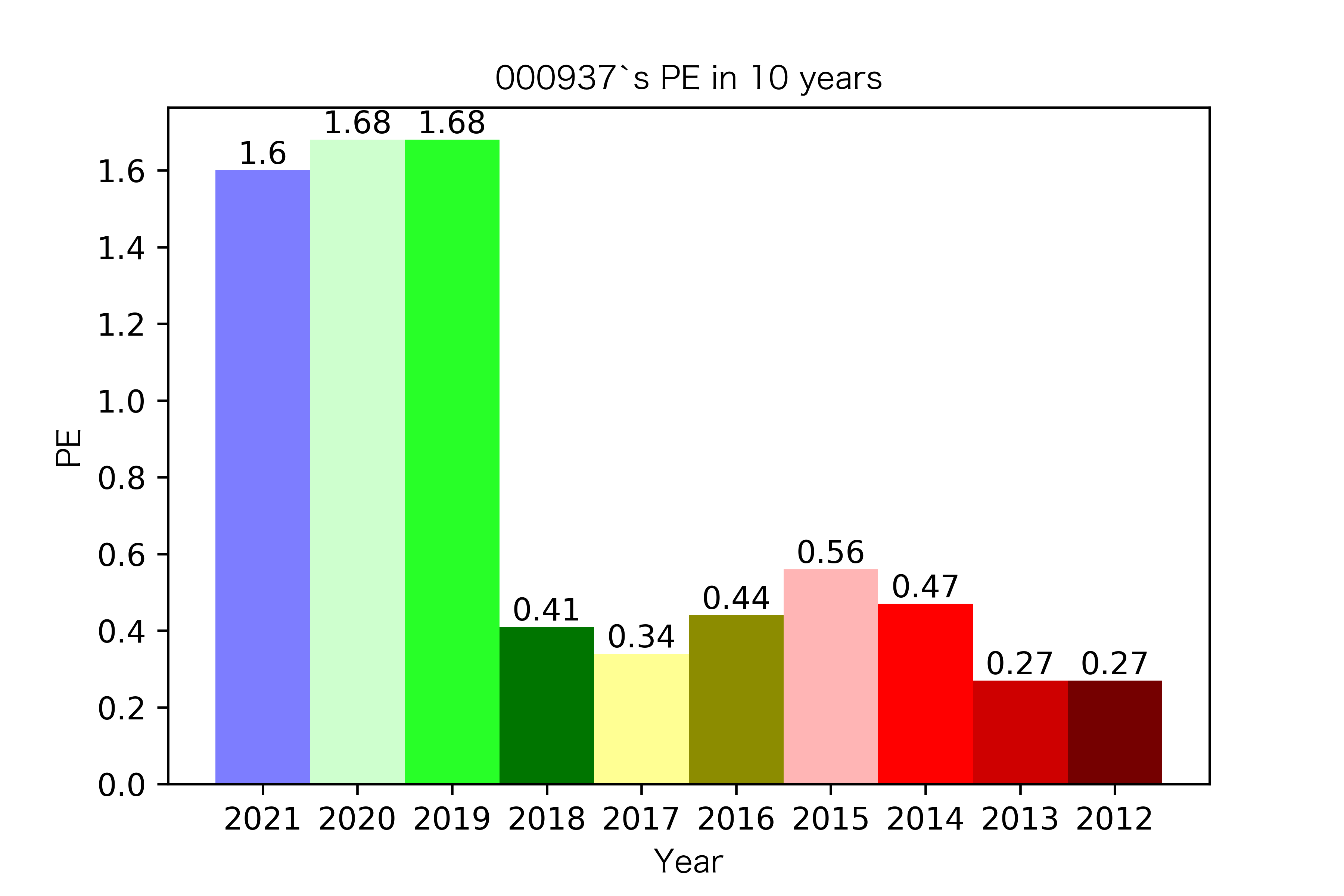
各公司每股收益对比
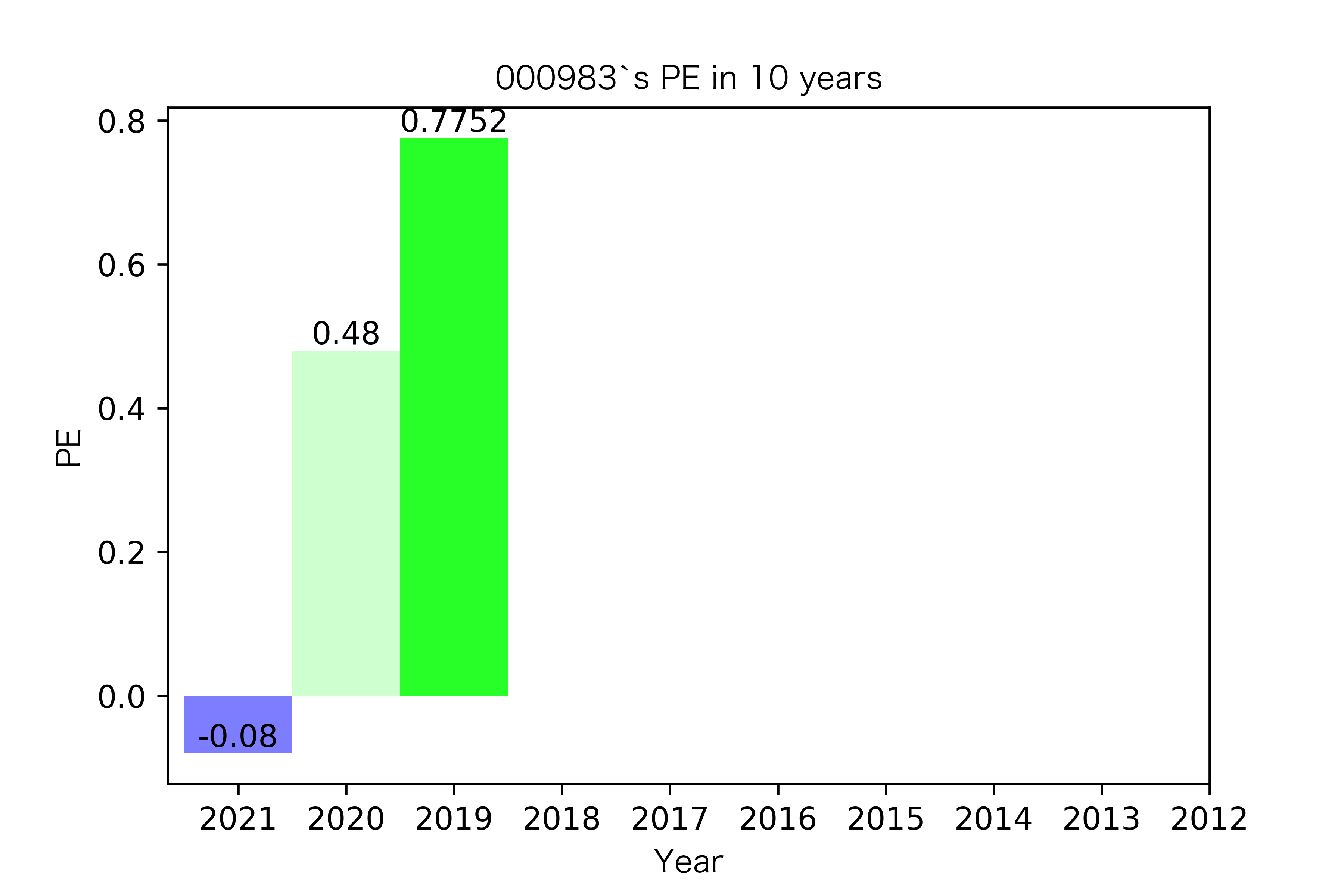
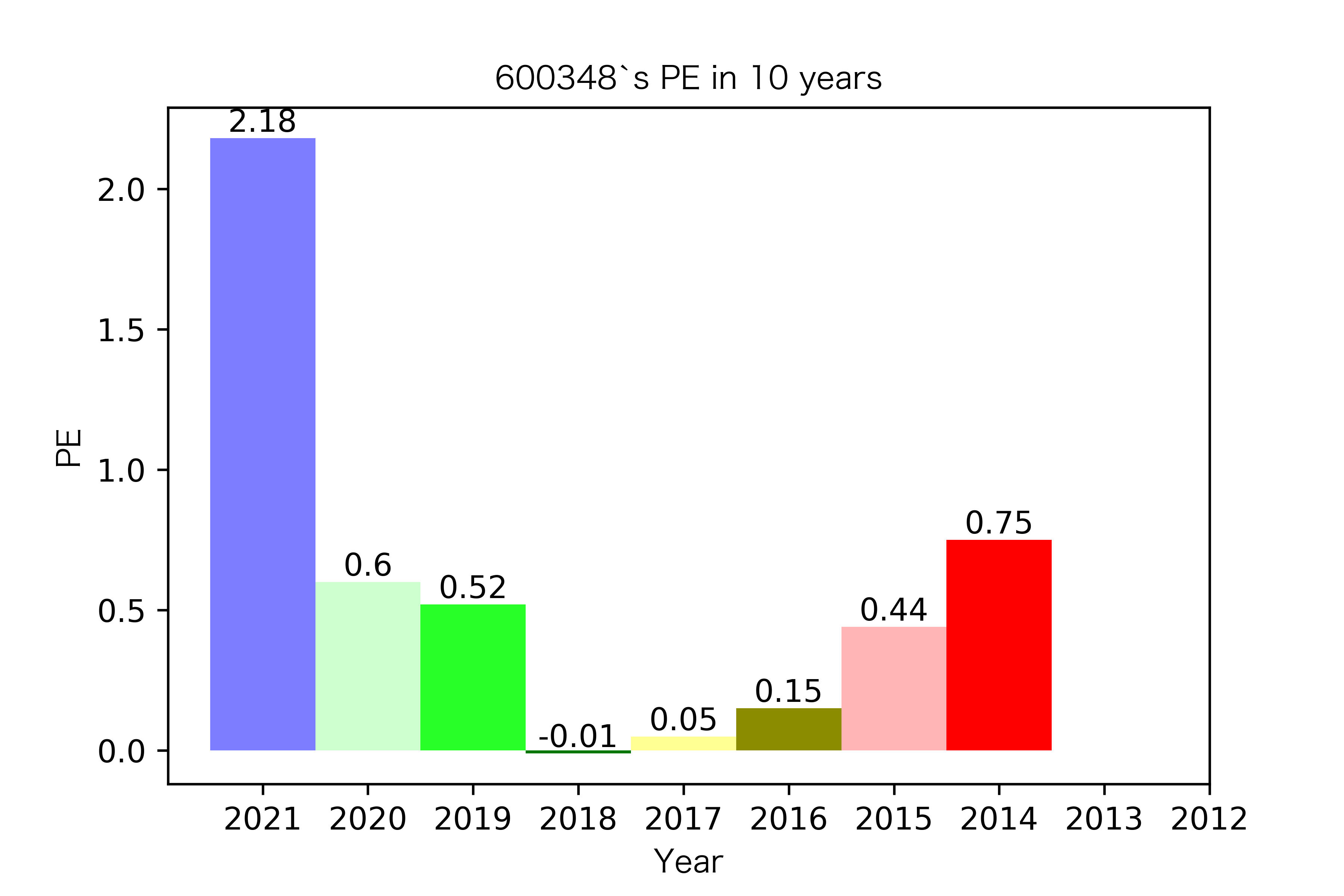
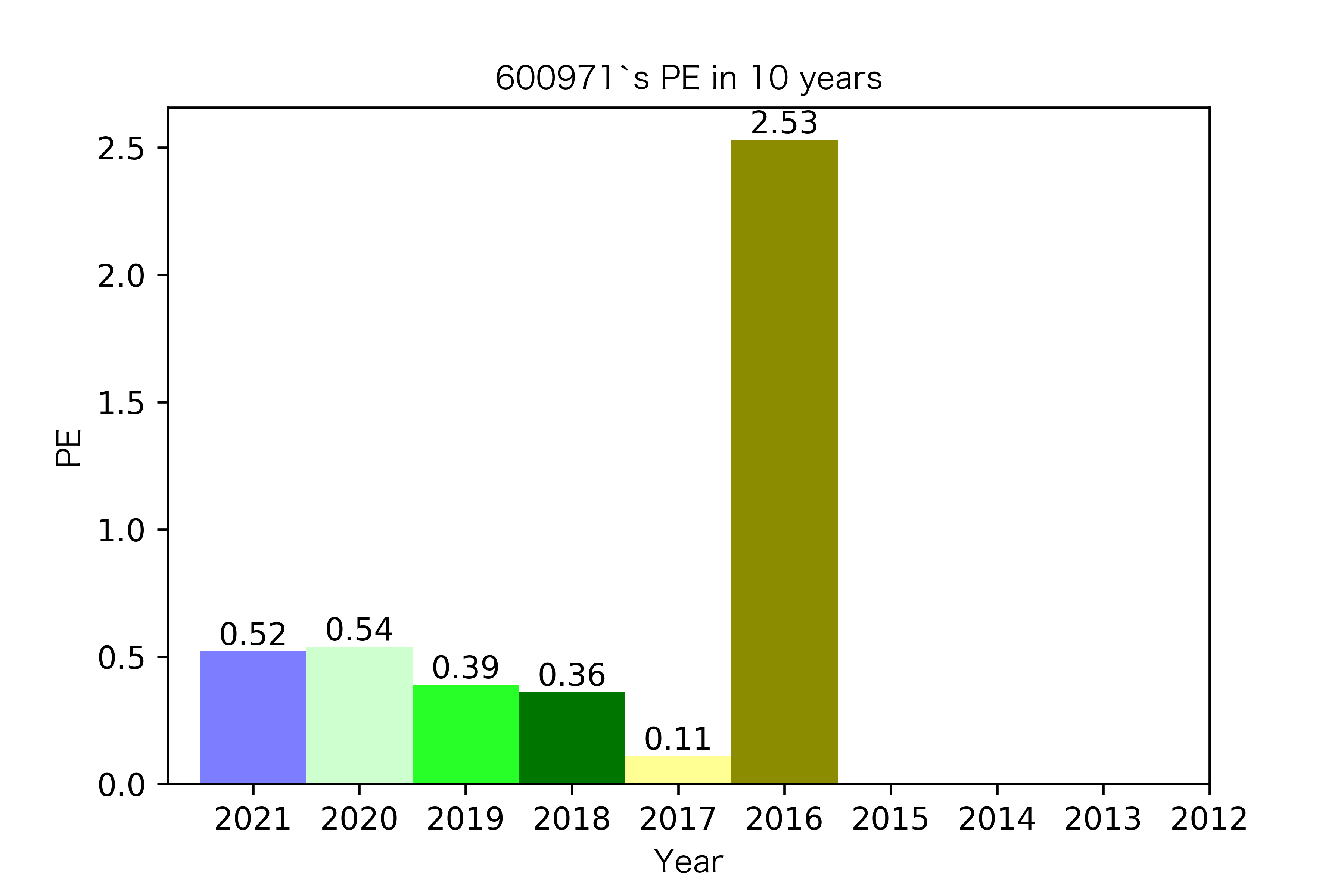
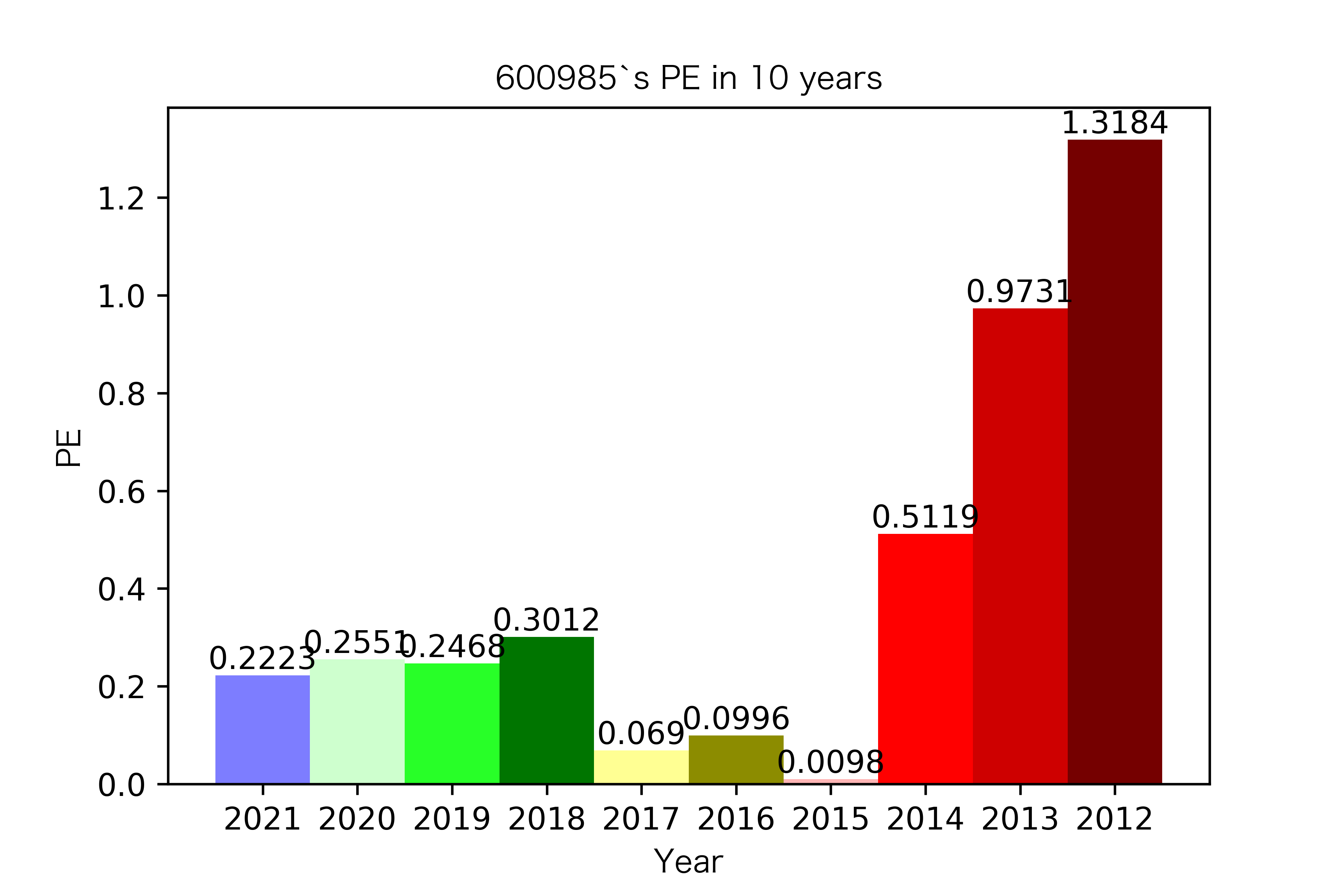
恒源煤电自2016年上市,在2021年不仅实现了自身近10年内的最高营业收入,也是在所选出平均营业收入最高的10家公司中远超实现营业收入远超其他公司。
昊华能源自2013年上市以来,营业收入的表现在2014-2018年都是行业内佼佼者,但从2019年开始,冀中能源的经营开始突飞猛进。但在此之前,冀中能源的表现在这10家公司里并不惹人注目,甚至收入远低于其他的公司。
其他的公司的营业收入基本上没有较大的起伏,略有波动,相对来说较为平稳。并且大多公司在2016年都达到至低点,原因是在那段时期受到宏观经济的影响,所以大部分公司的表现都不如前后的年份。
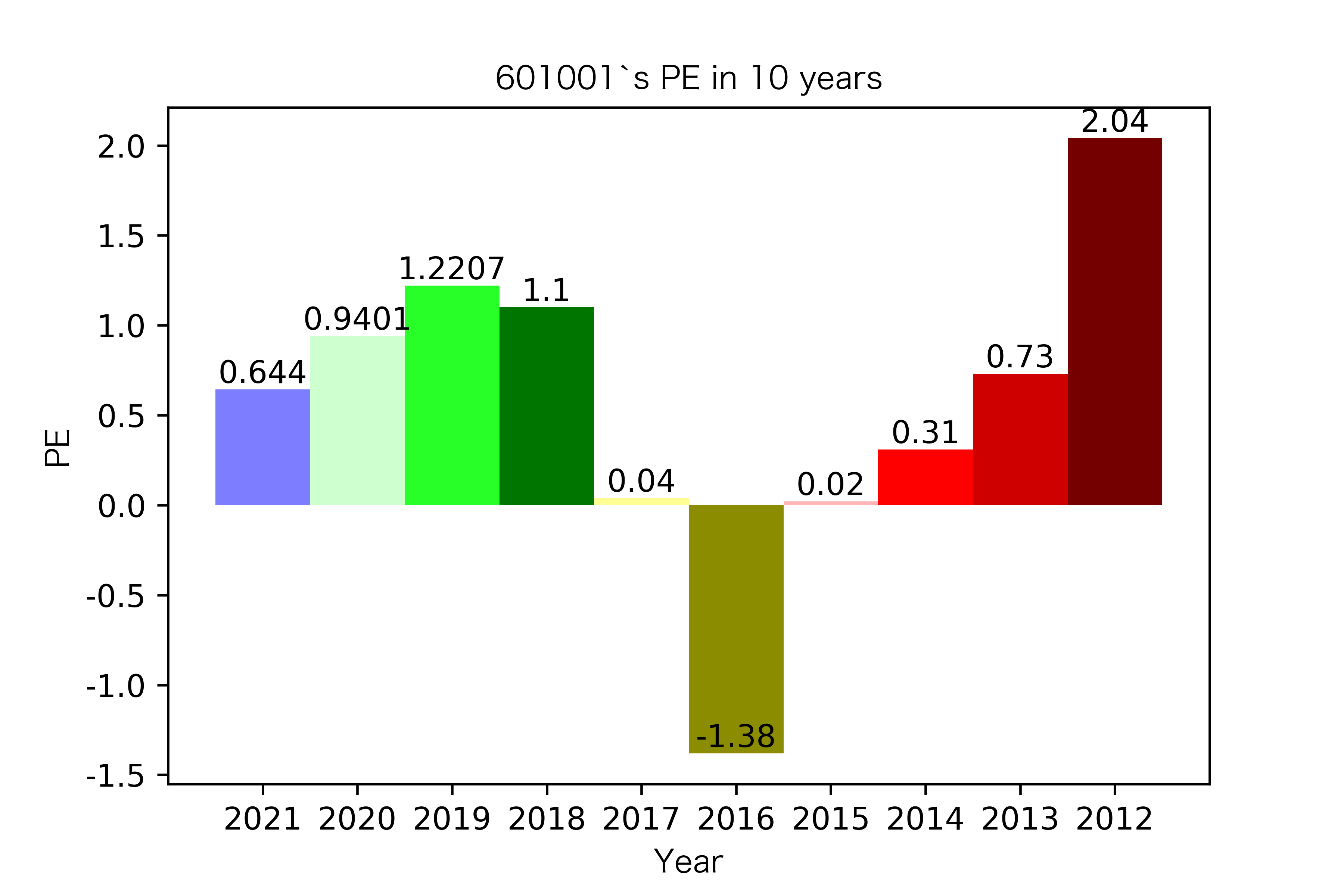
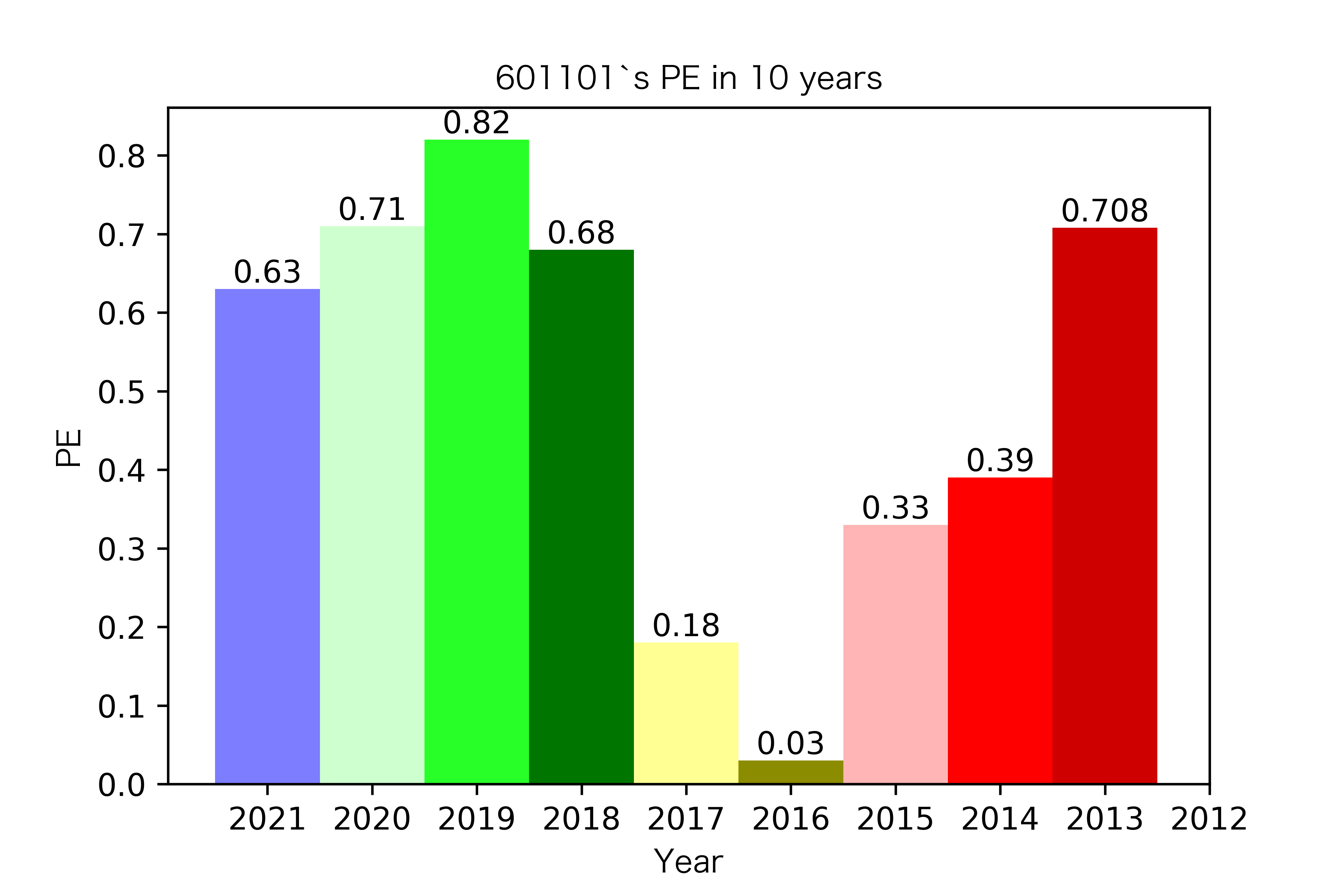
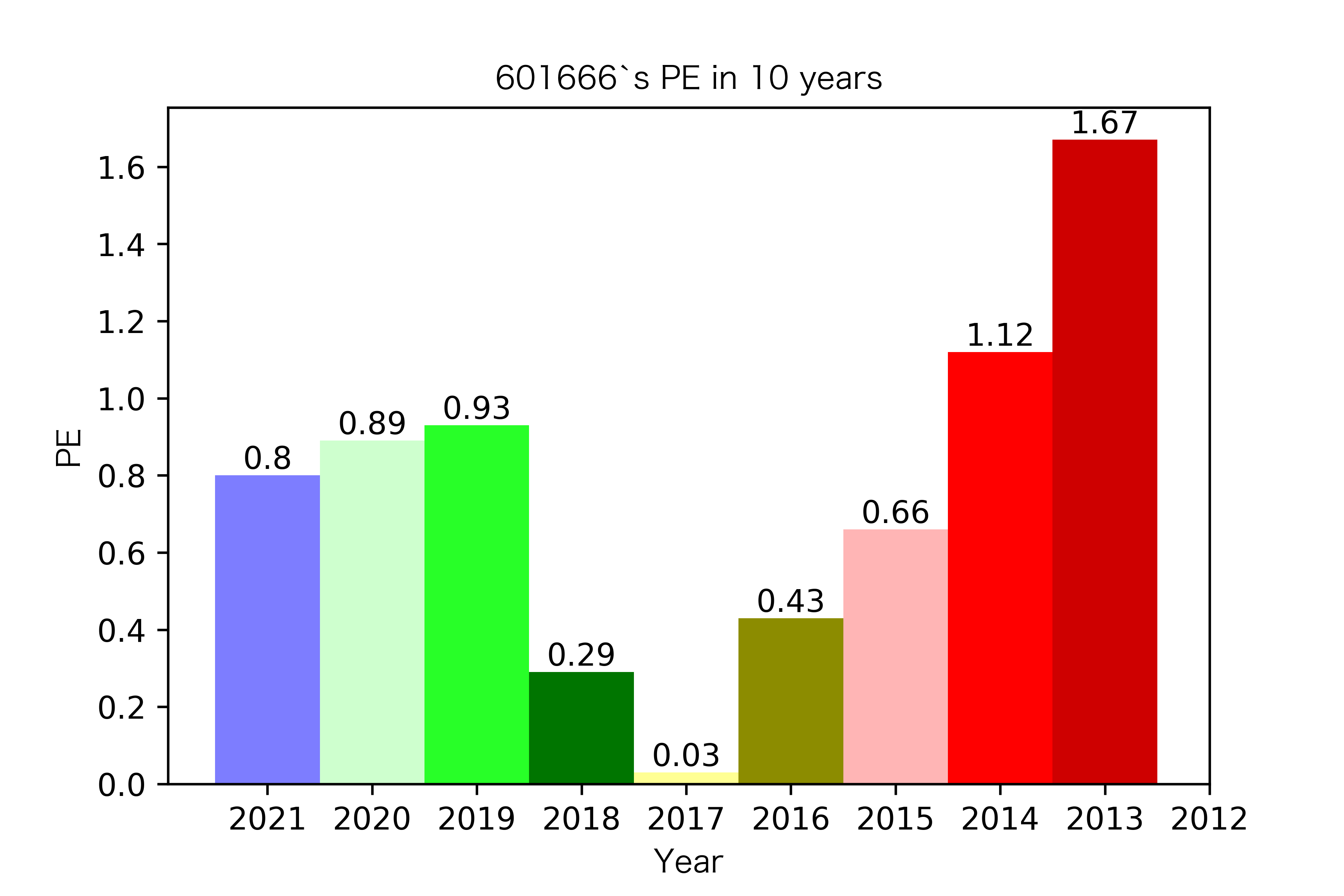
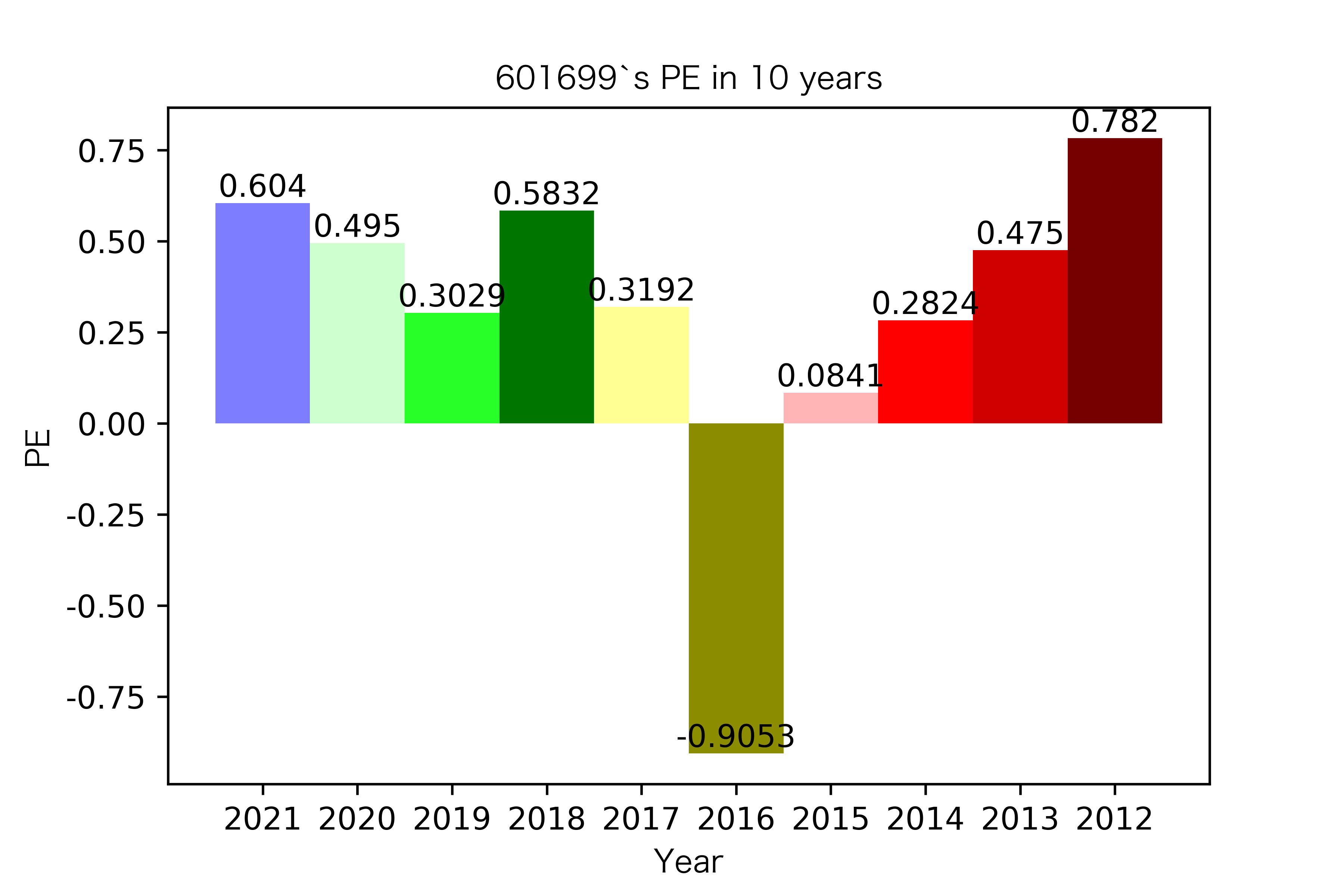
纵观每股收益的年份对比图,可见冀中能源的每股收益通常都较高。
大部分公司每年的每股收益都是正的,但华阳股份在10年中有3年的每股收益都是负的,是出现次数最多的公司。
总体来说每股收益的变动不是很大。但也可以看出在2016年很多公司的每股收益都下降,甚至有的公司为负。这也印证了上文营业收入的对比情况。
个人觉得这个实验并不是一个简单的事情,因为之前虽然上过python课,但用到的主要是numpy、pandas,没有学过正则表达式,也不知道如何网页爬取。所以这个实验从爬取网页到下载年报、从提取pdf中信息到对比作图得出结论,每一步我都花了很多时间去做。因为老师上课是用深交所的例子,但我的年报大部分是上交所的,所以第一步需要自己思考如何爬取网页,而不是简单的套用老师上课给的代码。这一步就需要对html解析有深刻的理解,从网页的检查开始,用鼠标找到需要的代码,复制到atom去解析,了解每一个标签对的含义,提出所需要的信息。
得到html后,需要从杂乱的网页源代码中提取网页下载链接,首先需要prettif,然后找到所需要的标签对的信息。这里上交所和深交所的不一样,深交所的下载链接是在attachpath,上交所在href。由于最开始深交所我也提成href了,导致下载的时候啥也没下下来,后来才知道是这里出了问题。
下载完成后,提取营业收入我也遇到了不少问题。一是营业收入的定位。这里我本是在老师上课讲的基础上,先定位,再提取。但我后来发现,直接提取pdf的所有文本也是可以的,并且代码更短。二是正则表达式的写法。因为每个公司的年报不同,年份久远的年报与现在的年报格式也不同,所以当提取出了问题,需要一个一个去对着看,然后修改。三是循环的写法。因为如果手动一个一个提的话,非常耗时,于是在最开始我尝试写循环把所有的年报一起提了,但是只要有一个提不出,整个就会报错。并且有时候虽然我一个一个运行是有结果的,但写进循环就会报错。所以我改成对每个公司写循环,一次可以提一个公司的10年年报,这样出错也能更好定位在哪个公司出问题,然后修改。虽然也不是特别聪明的办法,但也解决了我的问题。
虽然过程较为艰辛,但付出总是有收获的。我一向认为对知识的掌握最重要的是能够运用。而通过做这次实验报告,我将上课学习到的内容加以实践,加深了我对正则表达式、网页爬虫的理解,也见识到python的巨大作用。同时也加深了我对煤炭开采和洗选行业的理解和认识。
事实上,这门课的许多知识都我都很容易遗忘,我在这次作业遇到问题的时候,是重新看了老师上课的录屏的,所以很感谢老师发了录屏。我觉得python基础和记忆力实在是非常重要,同时也需要多加练习才能避免遗忘。在未来的学习中,我要更加注意这方面,打好基础。
在开始这个作业之前,我下载PyMuPDF的问题其实我自己在网上也搜了很久,但都不太行,最终多亏老师解答了。不论是邮件还是线下,每次问老师问题,老师都非常耐心,很感谢吴老师对我在这门课中的帮助!