於心怡的作业三
代码
# -*- coding: utf-8 -*-
"""
Created on Wed May 11 17:33:21 2022
@author: 於心怡、郭嘉懿、傅元娴
"""
#输入学生姓名自动提取其被分配到的行业中在深交所上市的一家公司近十年的年报
import pdfplumber
import pandas as pd
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import time
import os
import requests
#定义所需函数
'''
根据学生姓名匹配被分配到的行业于深市上市的公司
'''
def Pdf_extract_table(filename):
pdf =pdfplumber.open(filename)
page_count = len(pdf.pages)
data = []
for i in range(page_count):
data += pdf.pages[i].extract_table()
pdf.close()
return data
def Get_sz(data):
sz=['200','300','301','00','080'] #深市股票代码A股是以000开头;深市B股代码是以200开头;中小板股票以002开头;
#深市创业板的股票是以300、301开头(比如第一只创业板股票特锐德)。
#另外新股申购代码以00开头、配股代码以080开头。
lst = [ x for x in data for startcode in sz if x[3].startswith(startcode)==True ]
df = pd.DataFrame(lst,columns=data[0]).iloc[:,1:]
df = df.ffill()
return df
def InputStu():
Names = str(input('请输入姓名,以空格隔开:'))
Namelist = Names.split()
return Namelist
def Match(Namelist,assignment):
match = pd.DataFrame()
for name in Namelist:
match = pd.concat([match,assignment.loc[assignment['完成人']==name]])
Number = match['行业'].tolist()
return Number
def SelectMode(mode,matched,df):
df_final = pd.DataFrame()
if mode == 'first':
for num in matched:
df_final = pd.concat([df_final,df.loc[df['行业大类代码']==num].head(1)])
elif mode == 'random':
for num in matched:
df_final = pd.concat([df_final,df.loc[df['行业大类代码']==num].sample(1)])
return df_final
'''
利用selenium爬取所需公司年报
'''
#这里别忘了根据个人浏览器定义函数里的browser
def InputTime(start,end): #找到时间输入窗口并输入时间
START = browser.find_element(By.CLASS_NAME,'input-left')
END = browser.find_element(By.CLASS_NAME,'input-right')
START.send_keys(start)
END.send_keys(end + Keys.RETURN)
def SelectReport(kind): #挑选报告的类别
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
if kind == 1:
browser.find_element(By.LINK_TEXT,'一季度报告').click()
elif kind == 2:
browser.find_element(By.LINK_TEXT,'半年报告').click()
elif kind == 3:
browser.find_element(By.LINK_TEXT,'三季度报告').click()
elif kind == 4:
browser.find_element(By.LINK_TEXT,'年度报告').click()
def SearchCompany(name): #找到搜索框,通过股票简称查找对应公司的报告
Searchbox = browser.find_element(By.ID, 'input_code') # Find the search box
Searchbox.send_keys(name + Keys.RETURN)
def Clearicon(): #清除选中上个股票的历史记录
browser.find_elements(By.CLASS_NAME,'icon-remove')[-1].click()
def Clickonblank(): #点击空白
ActionChains(browser).move_by_offset(200, 100).click().perform()
def Save(filename,content):
f = open(filename+'.html','w',encoding='utf-8')
f.write(content)
f.close()
'''
解析html获取年报表格(代码来源于吴老师上课分享,修改了部分笔误)
'''
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
# 获得证券的代码和公告时间
p_a = re.compile('<a.*?>(.*?)</a>', re.DOTALL)
p_span = re.compile('<span.*?>(.*?)</span>', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
# 将txt_to_df赋给self
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('<tr>(.*?)</tr>', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('<td.*?>(.*?)</td>', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
# 获得下载链接
def get_link(self, txt):
p_txt = '<a.*?attachpath="(.*?)".*?href="(.*?)".*?<span.*?>(.*?)</span>'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix_href
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
'''
过滤年报并下载文件
'''
def Readhtml(filename):
f = open(filename+'.html', encoding='utf-8')
html = f.read()
f.close()
return html
def tidy(df): #清除“摘要”型、“(已取消)”型文件
d = []
for index, row in df.iterrows():
ggbt = row[2]
a = re.search("摘要|取消", ggbt)
if a != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
def Loadpdf(df):#用于下载文件
d1 = {}
for index, row in df.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
with open (key+".pdf", "wb") as code:
code.write(f.content)
#操作代码
'''
第一步,根据学生姓名自动挑选出所分配行业于深市上市的公司(第一家或随机)
'''
print('(读取解析行业分类文件中,这可能需要10秒)')
table = Pdf_extract_table("industry.pdf")
asign = pd.read_csv('001班行业安排表.csv',converters={'行业':str})[['行业','完成人']] #这里要注意把行业代码转为字符串,不然会失去开头的0
SZ = Get_sz(table)
Names = InputStu()
MatchedI = Match(Names,asign)
mode = str(input('''
【请选择模式】:
默认(取行业内第一家深市公司)输入"first"
行业内随机选择深市公司输入"random":'''))
df_final = SelectMode(mode,MatchedI,SZ)
Company = df_final['上市公司简称'].tolist()
'''
第二步爬取所需公司年报
'''
print('\n(爬取网页中......)')
browser = webdriver.Chrome()#这里别忘了根据个人浏览器选择
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
End = time.strftime('%Y-%m-%d', time.localtime())
InputTime('2012-01-01',End)
SelectReport(4) # 调用函数,选择“年度报告”
Clickonblank()
for name in Company:
SearchCompany(name)
time.sleep(1) # 延迟执行1秒,等待网页加载
html = browser.find_element(By.ID, 'disclosure-table')
innerHTML = html.get_attribute('innerHTML')
Save(name,innerHTML)
Clearicon()
browser.quit()
'''
第三步,解析html获取年报表格存储到本地并下载年报文件
'''
print('\n【开始保存年报】')
for name in Company:
html = Readhtml(name)
dt = DisclosureTable(html)
df = dt.get_data()
df1 = tidy(df)
df1.to_csv(name+'.csv',encoding='utf-8-sig')
os.makedirs(name,exist_ok=True)#创建用于放置下载文件的子文件夹
os.chdir(name)
Loadpdf(df1)
print(name+'年报已保存完毕。共',len(Company),'所公司,当前第',Company.index(name)+1,'所。')
os.chdir('../') #将当前工作目录爬到父文件夹,防止下一次循环找不到html文件
结果
运行交互截图
(如想更直观地了解操作流程可以查看郭嘉懿的作业三中的操作视频。)

保存下的文件:包含从网页上爬取的html代码(html文件),解析代码后得到的disclosure-table(csv文件),通过csv文件内的链接下载下来的年报(pdf文件)。选择first模式下载的公司为隆平高科,罗牛山,华斯股份,其余3家公司为random模式的结果)

first模式下选取的公司的年报
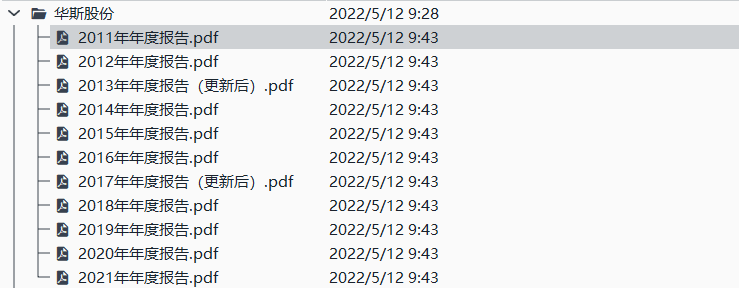
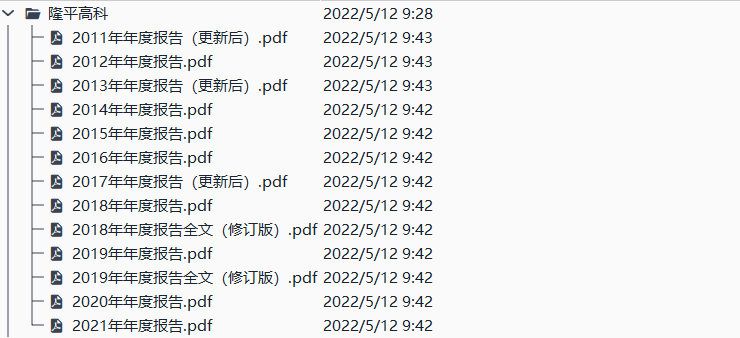
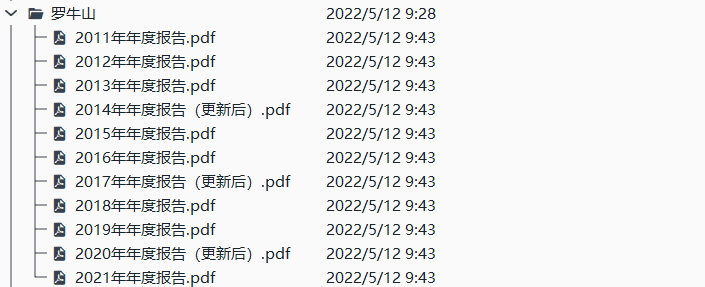
解析html得到的表格
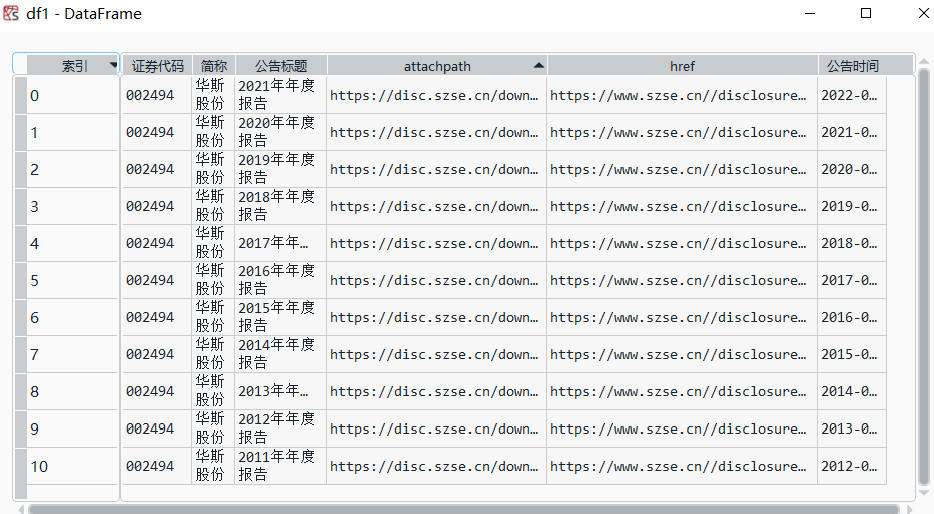
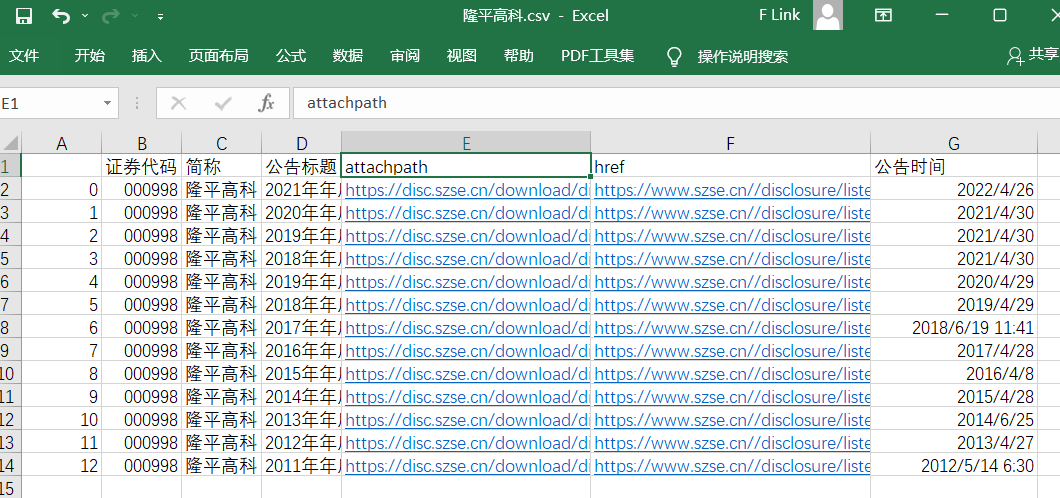
隆平高科.csv表格中attachpath列的链接连接到附件所在的目录,直接点击即可下载(作业中的实现自动下载就是使用访问attachpath的方法);href列的链接连接到报告所在的网页。
解释
仅需要输入学生姓名即可自动下载分配到行业的年报,并且过滤掉已取消版,摘要,只留下最新版本的年度报告。本代码所实现的自动化下载大致通过四步实现。
第一步根据输入的学生姓名,在行业安排文件中匹配到该学生的行业代码。在行业分类表格中筛选出在深交所上市的公司,再根据学生的行业代码,得到符合行业的公司简称列表。
第二步利用selenium模拟鼠标点击筛选所需公司的年报,并存下年报表格的html源码。
第三步解析html源码,转化为对应的表格。
第四步清除表格里标题为XXX(已取消),XXX(年度报告摘要)的行,保留下最新版的年报。再通过访问新表格里的attachpath列里的链接,下载pdf格式的年报。
附:代码相关文件
如果你对这个代码感兴趣,欢迎您下载相关文件自己进行尝试(并且帮我们找一下可能存在的bug) X )
源代码
homework3.py
相关文件
2021年3季度上市公司行业分类结果
001班安排表.csv