傅元娴的作业三
代码
import pdfplumber
import pandas as pd
import re
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.common.action_chains import ActionChains
import time
import os
import requests
'''
第一步,根据学生姓名自动挑选出所分配行业于深市上市的公司(第一家或随机)
'''
def Pdf_extract_table(filename):
pdf =pdfplumber.open(filename)
page_count = len(pdf.pages)
data = []
for i in range(page_count):
data += pdf.pages[i].extract_table()
pdf.close()
return data
def Get_sz(data):
sz=['200','300','301','00','080'] #深市股票代码A股是以000开头;深市B股代码是以200开头;中小板股票以002开头;
#深市创业板的股票是以300、301开头(比如第一只创业板股票特锐德)。
#另外新股申购代码以00开头、配股代码以080开头。
data2 = [ x for x in data for string in sz if x[3].startswith(string)==True ]
df = pd.DataFrame(data2,columns=data[0]).iloc[:,1:]
df = df.ffill()
return df
def InputStu():
Names = str(input('请输入姓名,以空格隔开:'))
Namelist = Names.split()
return Namelist
def Match(Namelist,assignment):
match = pd.DataFrame()
for name in Namelist:
match = match.append(assignment.loc[assignment['完成人']==name])
Number = match['行业'].tolist()
return Number
def SelectMode(mode,matched,df):
df_final = pd.DataFrame()
if mode == 'first':
for num in matched:
df_final = df_final.append(df.loc[df['行业大类代码']==num].head(1))
elif mode == 'random':
for num in matched:
df_final = df_final.append(df.loc[df['行业大类代码']==num].sample(1))
return df_final
table = Pdf_extract_table("industry.pdf")
asign = pd.read_csv('001班行业安排表.csv',converters={'行业':str})[['行业','完成人']]
SZ = Get_sz(table)
Names = InputStu()
MatchedI = Match(Names,asign)
mode = str(input('''
【请选择模式】:
默认(取行业内第一家深市公司)输入"first";
行业内随机选择深市公司输入"random":'''))
df_final = SelectMode(mode,MatchedI,SZ)
Company = df_final['上市公司简称'].tolist()
'''
第二步爬取所需公司年报
'''
browser = webdriver.Chrome()#这里别忘了根据个人浏览器选择
browser.get('https://www.szse.cn/disclosure/listed/fixed/index.html')
#获取所需公司年报的位置
def InputTime(start,end):
START = browser.find_element(By.CLASS_NAME,'input-left') #通过webdriver对象的find_element定位指定元素
END = browser.find_element(By.CLASS_NAME,'input-right')
START.send_keys(start)#将消息发送到活动窗口
END.send_keys(end + Keys.RETURN)
#挑选报告的类别
def SelectReport(kind):
browser.find_element(By.LINK_TEXT,'请选择公告类别').click()
if kind == 1:
browser.find_element(By.LINK_TEXT,'一季度报告').click()
elif kind == 2:
browser.find_element(By.LINK_TEXT,'半年报告').click()
elif kind == 3:
browser.find_element(By.LINK_TEXT,'三季度报告').click()
elif kind == 4:
browser.find_element(By.LINK_TEXT,'年度报告').click()
#通过股票简称查找对应公司的报告
def SearchCompany(name):
Searchbox = browser.find_element(By.ID, 'input_code') # Find the search box
Searchbox.send_keys(name + Keys.RETURN)
def Clearicon():#清除选中上个股票的历史记录
browser.find_elements_by_class_name('icon-remove')[-1].click()
def Clickonblank():
ActionChains(browser).move_by_offset(200, 100).click().perform() #点击空白
def Save(filename,content):
f = open(filename+'.html','w',encoding='utf-8')
f.write(content)
f.close()
End = time.strftime('%Y-%m-%d', time.localtime())
InputTime('2012-01-01',End)
SelectReport(4) # 调用函数,选择“年度报告”
Clickonblank()
for name in Company:
SearchCompany(name)
time.sleep(1) # 延迟执行1秒
html = browser.find_element(By.ID, 'disclosure-table')
innerHTML = html.get_attribute('innerHTML')
Save(name,innerHTML)
Clearicon()
browser.quit()
'''
第三步,解析html获取表格
'''
class DisclosureTable():
'''
解析深交所定期报告页搜索表格
'''
def __init__(self, innerHTML):
self.html = innerHTML
self.prefix = 'https://disc.szse.cn/download'
self.prefix_href = 'https://www.szse.cn/'
# 获得证券的代码和公告时间
p_a = re.compile('<a.*?>(.*?)</a>', re.DOTALL)
p_span = re.compile('<span.*?>(.*?)</span>', re.DOTALL)
self.get_code = lambda txt: p_a.search(txt).group(1).strip()
self.get_time = lambda txt: p_span.search(txt).group(1).strip()
# 将txt_to_df赋给self
self.txt_to_df()
def txt_to_df(self):
# html table text to DataFrame
html = self.html
p = re.compile('<tr>(.*?)</tr>', re.DOTALL)
trs = p.findall(html)
p2 = re.compile('<td.*?>(.*?)</td>', re.DOTALL)
tds = [p2.findall(tr) for tr in trs[1:]]
df = pd.DataFrame({'证券代码': [td[0] for td in tds],
'简称': [td[1] for td in tds],
'公告标题': [td[2] for td in tds],
'公告时间': [td[3] for td in tds]})
self.df_txt = df
# 获得下载链接
def get_link(self, txt):
p_txt = '<a.*?attachpath="(.*?)".*?href="(.*?)".*?<span.*?>(.*?)</span>'
p = re.compile(p_txt, re.DOTALL)
matchObj = p.search(txt)
attachpath = matchObj.group(1).strip()
href = matchObj.group(2).strip()
title = matchObj.group(3).strip()
return([attachpath, href, title])
def get_data(self):
get_code = self.get_code
get_time = self.get_time
get_link = self.get_link
#
df = self.df_txt
codes = [get_code(td) for td in df['证券代码']]
short_names = [get_code(td) for td in df['简称']]
ahts = [get_link(td) for td in df['公告标题']]
times = [get_time(td) for td in df['公告时间']]
#
prefix = self.prefix
prefix_href = self.prefix
df = pd.DataFrame({'证券代码': codes,
'简称': short_names,
'公告标题': [aht[2] for aht in ahts],
'attachpath': [prefix + aht[0] for aht in ahts],
'href': [prefix_href + aht[1] for aht in ahts],
'公告时间': times
})
self.df_data = df
return(df)
def Readhtml(filename):
f = open(filename+'.html', encoding='utf-8')
html = f.read()
f.close()
return html
def tidy(df):#清除“摘要”型、“(已取消)”型文件
d = []
for index, row in df.iterrows():
ggbt = row[2]
a = re.search("摘要|取消", ggbt)
if a != None:
d.append(index)
df1 = df.drop(d).reset_index(drop = True)
return df1
def Loadpdf(df):#用于下载文件
d1 = {}
for index, row in df.iterrows():
d1[row[2]] = row[3]
for key, value in d1.items():
f = requests.get(value)
with open (key+".pdf", "wb") as code:
code.write(f.content)
for name in Company:
html = Readhtml(name)
dt = DisclosureTable(html)
df = dt.get_data()
df1 = tidy(df)
df1.to_csv(name+'.csv',encoding='utf-8-sig')
os.makedirs(name,exist_ok=True)#创建用于放置下载文件的子文件夹
os.chdir(name)
Loadpdf(df1)
print(name+'年报已保存完毕。共',len(Company),'所公司。当前第',Company.index(name)+1,'所。')
os.chdir('../')
结果

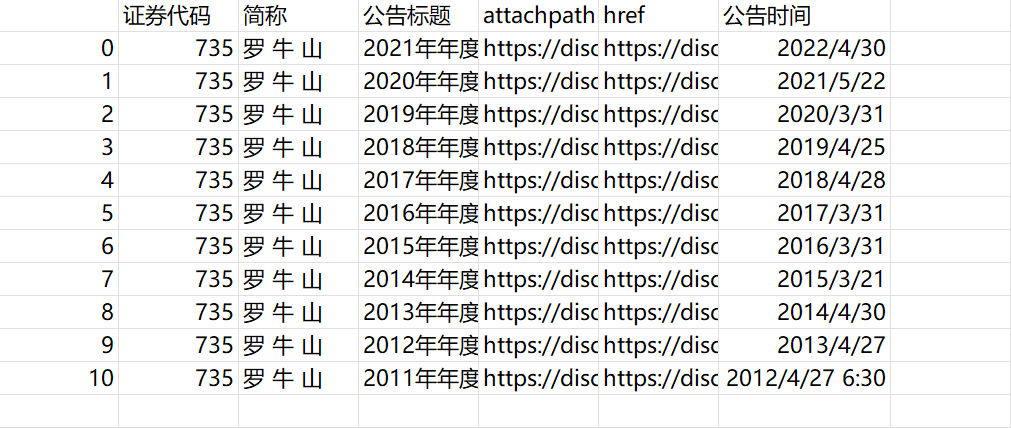
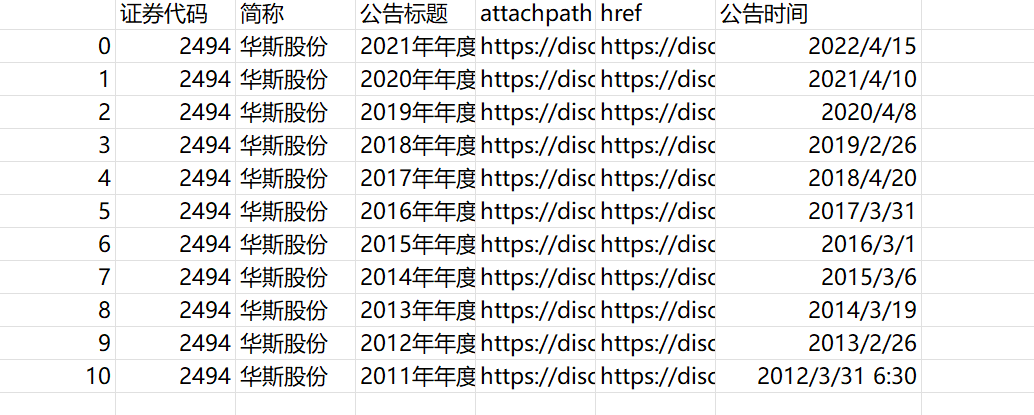
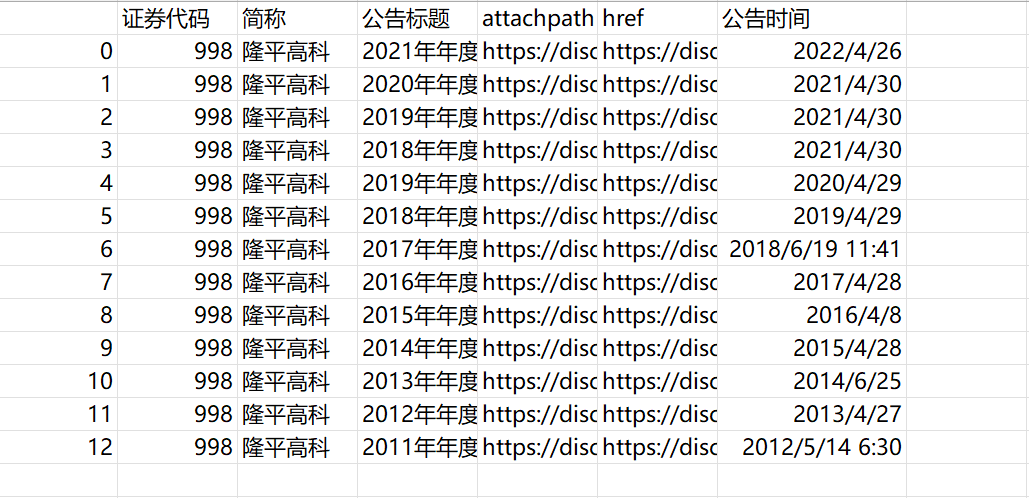
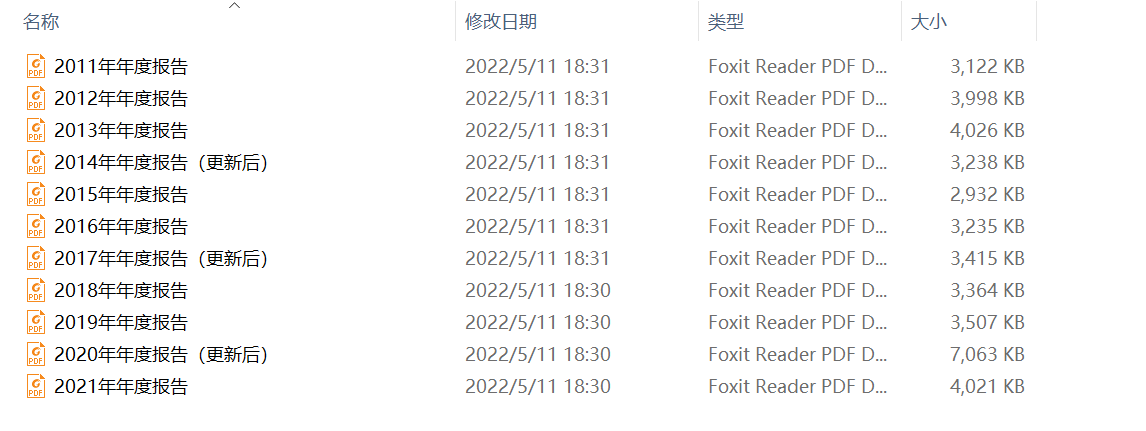
解释
- 根据学生姓名自动挑选出所分配行业于深市上市的公司(第一家或随机),我们选择输入first,即获取的第一家公司的报告
- 爬取选中的公司的网址等信息,生成html文件
- 解析html文件,获得下载链接并保存在csv文件中
- 最后实现自动下载文件、创建公司文件夹,并分别保存在不同的公司文件夹中
- 运行的过程中,我们只需要输入小组成员的姓名,再选择下载的文件即可实现自动获取年报