In [1]:
import pandas as pd
import os
import requests
def get_report(code:list,start,end):
#此函数用于下载股票的年报数据,code必须是列表格式
#start与end必须是yyyy-mm-dd的日期文本格式
#使用范例1,下载单个股票的年报:get_report(['600519'],'2018-01-01','2021-01-01')
#使用范例2,下载多个股票的年报:get_report(['600519','300433','000002'],'2018-01-01','2021-01-01')
url1='http://www.cninfo.com.cn/new/data/szse_stock.json'
s2=requests.get(url1)
df2=eval(s2.text)
df2=pd.DataFrame(df2['stockList'])
url='http://www.cninfo.com.cn/new/hisAnnouncement/query'
headers={'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Content-Length': '201',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'JSESSIONID=6C58E377D0840FB0378B5D5ABAC71926; insert_cookie=37836164; _sp_ses.2141=*; routeId=.uc1; SID=638195d3-528f-4287-a832-c0aa7f38c3aa; _sp_id.2141=07956701-cde3-401e-a436-9365e13446b8.1619756100.1.1619756924.1619756100.264b867d-32e8-4399-8dd1-8dec91949ac6',
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Proxy-Connection': 'keep-alive',
'Referer': 'http://www.cninfo.com.cn/new/commonUrl/pageOfSearch?url=disclosure/list/search&lastPage=index',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'}
for i in code:
org=list(df2[df2['code']==i]['orgId'])[0]
data={'pageNum': '1',
'pageSize': '30',
'column': 'szse',
'tabName': 'fulltext',
'plate':'',
'stock': '{},{}'.format(i,org),
'searchkey':'',
'secid':'',
'category': 'category_ndbg_szsh',
'trade':'',
'seDate': '{}~{}'.format(start,end),
'sortName':'',
'sortType':'',
'isHLtitle': 'true'}
s1=requests.post(url,data=data,headers=headers)
null=''
false=''
true=''
df=eval(s1.text)
df=pd.DataFrame(df['announcements'])
name=list(list(df2[df2['code']==i]['zwjc'])[0]+df['announcementTitle'])
name=[i.replace('*','') for i in name]
lists=list(df['announcementId'])
for i,j in zip(lists,name):
down_url='http://www.cninfo.com.cn/new/announcement/download?bulletinId={}'.format(i)
file=requests.get(down_url)
f=open(j+'.pdf','wb+')
f.write(file.content)
f.close()
print(j+'下载完成')
li=['002460','002466','603799','002240','300618','002340']
name=['赣锋锂业','天齐锂业','华友钴业','盛新锂能','寒锐钴业','格林美']
now_path=os.getcwd()
paths=[now_path+'\\'+i for i in name]
[os.mkdir(i) for i in paths]
li=[[i] for i in li]
for path,k in zip(paths,li):
os.chdir(path)
get_report(k,'2011-12-12','2022-05-12')
files=os.listdir(path)
remove=['摘要','已取消']
for i in files:
n=0
for j in remove:
if j in i and n==0:
os.remove(path+'\\'+i)
print(i+' 已删除')
n+=1
In [48]:
import fitz
from bs4 import BeautifulSoup
import re
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import pdfplumber
import time
In [49]:
# 提取营业收入
def getText(pdf): # 获取文本
text = ''
doc = fitz.open(pdf)
for page in doc:
text += page.getText()
doc.close()
text = text.replace(" "," \n")
text = text.replace("\n\n","\n")#由于后续subp匹配过程中,有的数字后面没有换行符,无法进行非贪婪的匹配,所以通过文本内部符号替换
return(text)
def get_content(pdf):#定义函数获取营业收入所在年报内容的位置
text = getText(pdf)
p = re.compile('(?<=\\n)\D、\s*\D*?主要\D*?数据\D*?\s*(?=\\n)(.*?)经营活动产生的',re.DOTALL)#定位各个年报固定位置的内容
content = p.search(text).group(0)
return(content)
def parse_data_line(pdf): #定义函数单独提取营业收入所在行的内容
content = get_content(pdf)
subp = "([0-9,.%\- ]*?)\n"
psub = "%s%s%s%s" % (subp,subp,subp,subp)
p =re.compile("(?<=\\n)营业(\D*?\n)+%s" % psub) #定义营业收入所在行的内容
lines = p.search(content)
lines = lines[0]
return(lines)
In [50]:
#提取每股净收益
def get_profit(pdf):
text = getText(pdf)
p = re.compile('(?<=\\n)\D、\s*\D*?主要\D*?指标\D*?\s*(?=\\n)(.*?)稀释每股',re.DOTALL)
profit = p.search(text).group(0)
return(profit)
def profit_data_line(pdf):
profit = get_profit(pdf)
subp = "([0-9,.%\- ]*?)\n"
psub = "%s%s%s%s" % (subp,subp,subp,subp)
p =re.compile("(?<=\\n)基本每股收益(\D*?\n)+%s" % psub)#定义每股收益所在行的内容
lines_profit = p.search(profit)
lines_profit = lines_profit[0]
return(lines_profit)
In [ ]:
path_1 = os.getcwd()+ '\pdf'
dir_list = [(path_1 + '\\' + x) for x in os.listdir(path_1)]
path_list = []
for x in dir_list:
list_1 = [(path_1 + '\\' + x) for x in os.listdir(x)]
path_list.append(list_1)
path_list
def read_from_pdf(file_path):
with open(file_path, 'rb') as file:
resource_manager = PDFResourceManager()
return_str = StringIO()
lap_params = LAParams()
device = TextConverter(resource_manager, return_str, laparams=lap_params)
process_pdf(resource_manager, device, file)
device.close()
content = return_str.getvalue()
return_str.close()
return re.sub('\s+', '', content)
data_list = []
for i in path_list:
for x in i:
list_2 = []
data_1 = read_from_pdf(x)
name_1 = re.findall(r'股票简称:(.*?)股票代码', data_1, re.S)[0]
num_1 = re.findall(r'股票代码:(.*?)披', data_1, re.S)[0]
add_1 = re.findall(r'公司办公地址:(.*?)号', data_1, re.S)
url_1 = re.findall(r'公司互联网网址:(.*?)公司电子', data_1, re.S)[0]
list_2.append(data_1)
list_2.append(name_1)
list_2.append(num_1)
list_2.append(add_1)
list_2.append(url_1)
data_list.append(list_2)
df = pd.Dataframe(data_list)
df.to_csv("./data_list.csv")
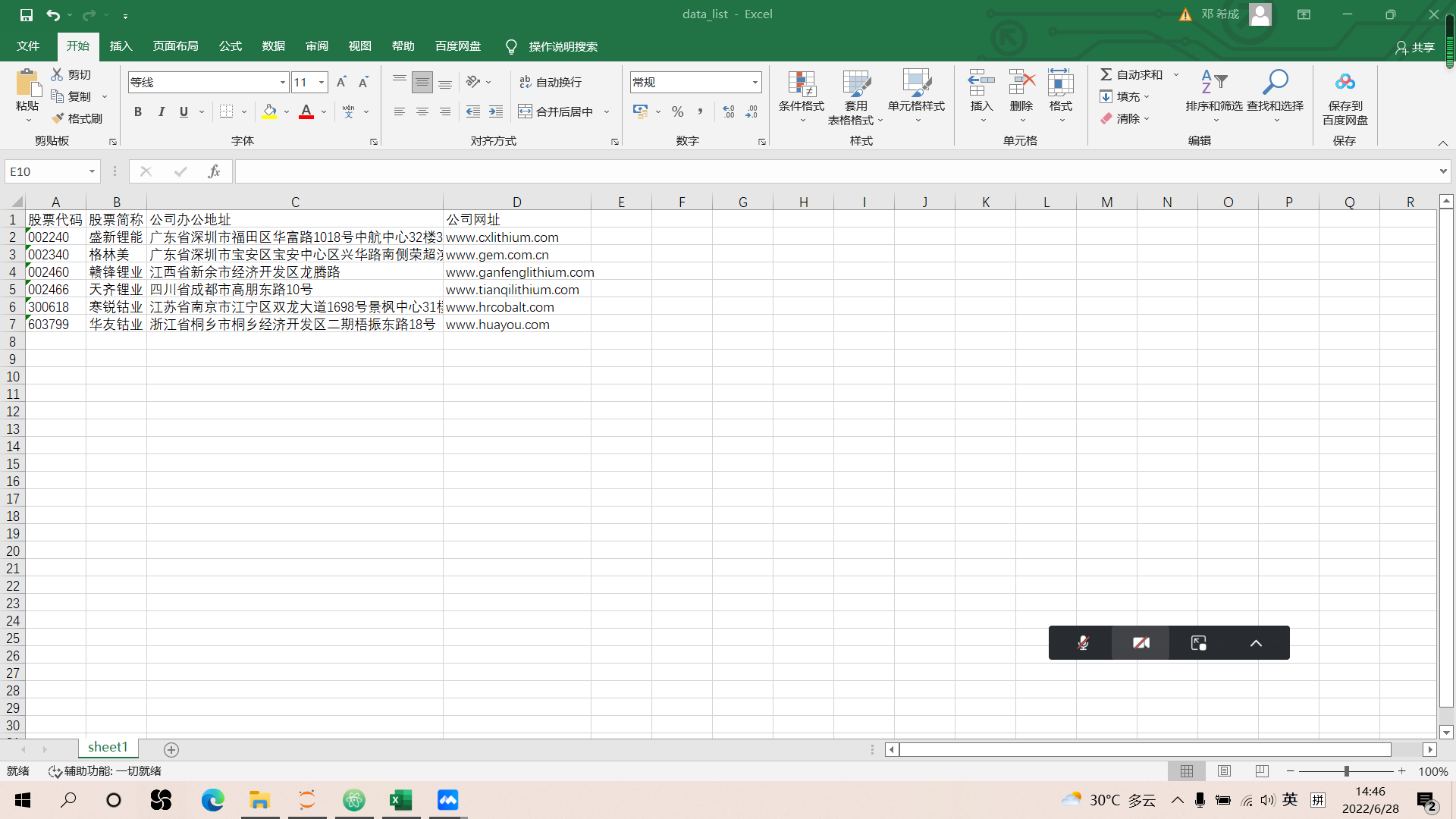
In [51]:
# 以下分别对上交所和深交所的年报文件夹运行
import os
os.chdir(r"C:\Users\11200\赣锋锂业")
filenames = os.listdir() #把代码所在文件夹的所有文件和文件名查找出来
pdf_list = [f for f in filenames if f.endswith('.pdf')]
df = pd.DataFrame(columns = ["name", "year", "pdf"])
df["name"] = [f[0:4] for f in pdf_list]
years = [f[4:8] for f in pdf_list]
df['year'] = years
df['pdf'] = pdf_list
df = df.sort_values(by='year', ascending=False)
In [52]:
df["pdf"]
Out[52]:
In [53]:
sale = []
profit =[]
for pdf in df['pdf']:
i=0
#year = pdf[4:9]
doc = fitz.open(pdf) #打开pdf
text = [page.getText() for page in doc]
text = ''.join(text)
p_re = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
revenue = p_re.search(text).group(1)
revenue = revenue.replace(',','') #把revenue里的逗号去掉
sale.append(revenue)
profit_gain = profit_data_line(pdf)
profit_gain = profit_gain.split("\n")
profit_gain = profit_gain[1]
profit.append(profit_gain)
In [54]:
data = pd.DataFrame()
data["sale"]=sale
data["profit"]=profit
data.index=df["year"]
In [60]:
data = data[::-1]
data
Out[60]:
In [61]:
data.to_csv(r"E:\360MoveData\Users\11200\Desktop\赣锋锂业.csv")
In [62]:
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
In [63]:
plt.figure()
plt.plot(data.index,data["sale"].astype(float),c="c")
plt.title("赣锋锂业营业收入")
plt.grid()
plt.show()
plt.figure()
plt.plot(data.index,data["profit"].astype(float),c="c")
plt.title("赣锋锂业每股收益")
plt.grid()
plt.show()


In [64]:
# 以下分别对上交所和深交所的年报文件夹运行
import os
os.chdir(r"C:\Users\11200\格林美")
filenames = os.listdir() #把代码所在文件夹的所有文件和文件名查找出来
pdf_list = [f for f in filenames if f.endswith('.pdf')]
df = pd.DataFrame(columns = ["name", "year", "pdf"])
df["name"] = [f[0:4] for f in pdf_list]
years = [f[4:8] for f in pdf_list]
df['year'] = years
df['pdf'] = pdf_list
df = df.sort_values(by='year', ascending=False)
df["pdf"]
Out[64]:
In [65]:
sale = []
profit =[]
for pdf in df['pdf']:
i=0
#year = pdf[4:9]
doc = fitz.open(pdf) #打开pdf
text = [page.getText() for page in doc]
text = ''.join(text)
p_re = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
revenue = p_re.search(text).group(1)
revenue = revenue.replace(',','') #把revenue里的逗号去掉
sale.append(revenue)
profit_gain = profit_data_line(pdf)
profit_gain = profit_gain.split("\n")
profit_gain = profit_gain[1]
profit.append(profit_gain)
In [66]:
data = pd.DataFrame()
data["sale"]=sale
data["profit"]=profit
data.index=df["year"]
In [67]:
data = data[::-1]
data
Out[67]:
In [68]:
data.to_csv(r"E:\360MoveData\Users\11200\Desktop\格林美.csv")
In [69]:
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
In [71]:
plt.figure()
plt.plot(data.index,data["sale"].astype(float),c="c")
plt.title("格林美营业收入")
plt.grid()
plt.show()
plt.figure()
plt.plot(data.index,data["profit"].astype(float),c="c")
plt.title("格林美每股收益")
plt.grid()
plt.show()


In [72]:
# 以下分别对上交所和深交所的年报文件夹运行
import os
os.chdir(r"C:\Users\11200\寒锐钴业")
filenames = os.listdir() #把代码所在文件夹的所有文件和文件名查找出来
pdf_list = [f for f in filenames if f.endswith('.pdf')]
df = pd.DataFrame(columns = ["name", "year", "pdf"])
df["name"] = [f[0:4] for f in pdf_list]
years = [f[4:8] for f in pdf_list]
df['year'] = years
df['pdf'] = pdf_list
df = df.sort_values(by='year', ascending=False)
df["pdf"]
sale = []
profit =[]
for pdf in df['pdf']:
i=0
#year = pdf[4:9]
doc = fitz.open(pdf) #打开pdf
text = [page.getText() for page in doc]
text = ''.join(text)
p_re = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
revenue = p_re.search(text).group(1)
revenue = revenue.replace(',','') #把revenue里的逗号去掉
sale.append(revenue)
profit_gain = profit_data_line(pdf)
profit_gain = profit_gain.split("\n")
profit_gain = profit_gain[1]
profit.append(profit_gain)
data = pd.DataFrame()
data["sale"]=sale
data["profit"]=profit
data.index=df["year"]
data = data[::-1]
data
data.to_csv(r"E:\360MoveData\Users\11200\Desktop\寒锐钴业.csv")
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure()
plt.plot(data.index,data["sale"].astype(float),c="c")
plt.title("寒锐钴业营业收入")
plt.grid()
plt.show()
plt.figure()
plt.plot(data.index,data["profit"].astype(float),c="c")
plt.title("寒锐钴业每股收益")
plt.grid()
plt.show()


In [73]:
# 以下分别对上交所和深交所的年报文件夹运行
import os
os.chdir(r"C:\Users\11200\华友钴业")
filenames = os.listdir() #把代码所在文件夹的所有文件和文件名查找出来
pdf_list = [f for f in filenames if f.endswith('.pdf')]
df = pd.DataFrame(columns = ["name", "year", "pdf"])
df["name"] = [f[0:4] for f in pdf_list]
years = [f[4:8] for f in pdf_list]
df['year'] = years
df['pdf'] = pdf_list
df = df.sort_values(by='year', ascending=False)
df["pdf"]
sale = []
profit =[]
for pdf in df['pdf']:
i=0
#year = pdf[4:9]
doc = fitz.open(pdf) #打开pdf
text = [page.getText() for page in doc]
text = ''.join(text)
p_re = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
revenue = p_re.search(text).group(1)
revenue = revenue.replace(',','') #把revenue里的逗号去掉
sale.append(revenue)
profit_gain = profit_data_line(pdf)
profit_gain = profit_gain.split("\n")
profit_gain = profit_gain[1]
profit.append(profit_gain)
data = pd.DataFrame()
data["sale"]=sale
data["profit"]=profit
data.index=df["year"]
data = data[::-1]
data
data.to_csv(r"E:\360MoveData\Users\11200\Desktop\华友钴业.csv")
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure()
plt.plot(data.index,data["sale"].astype(float),c="c")
plt.title("华友钴业营业收入")
plt.grid()
plt.show()
plt.figure()
plt.plot(data.index,data["profit"].astype(float),c="c")
plt.title("华友钴业每股收益")
plt.grid()
plt.show()


In [74]:
# 以下分别对上交所和深交所的年报文件夹运行
import os
os.chdir(r"C:\Users\11200\盛新锂能")
filenames = os.listdir() #把代码所在文件夹的所有文件和文件名查找出来
pdf_list = [f for f in filenames if f.endswith('.pdf')]
df = pd.DataFrame(columns = ["name", "year", "pdf"])
df["name"] = [f[0:4] for f in pdf_list]
years = [f[4:8] for f in pdf_list]
df['year'] = years
df['pdf'] = pdf_list
df = df.sort_values(by='year', ascending=False)
df["pdf"]
sale = []
profit =[]
for pdf in df['pdf']:
i=0
#year = pdf[4:9]
doc = fitz.open(pdf) #打开pdf
text = [page.getText() for page in doc]
text = ''.join(text)
p_re = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
revenue = p_re.search(text).group(1)
revenue = revenue.replace(',','') #把revenue里的逗号去掉
sale.append(revenue)
profit_gain = profit_data_line(pdf)
profit_gain = profit_gain.split("\n")
profit_gain = profit_gain[1]
profit.append(profit_gain)
data = pd.DataFrame()
data["sale"]=sale
data["profit"]=profit
data.index=df["year"]
data = data[::-1]
data
data.to_csv(r"E:\360MoveData\Users\11200\Desktop\盛新锂能.csv")
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure()
plt.plot(data.index,data["sale"].astype(float),c="c")
plt.title("盛新锂能营业收入")
plt.grid()
plt.show()
plt.figure()
plt.plot(data.index,data["profit"].astype(float),c="c")
plt.title("盛新锂能每股收益")
plt.grid()
plt.show()


In [75]:
# 以下分别对上交所和深交所的年报文件夹运行
import os
os.chdir(r"C:\Users\11200\天齐锂业")
filenames = os.listdir() #把代码所在文件夹的所有文件和文件名查找出来
pdf_list = [f for f in filenames if f.endswith('.pdf')]
df = pd.DataFrame(columns = ["name", "year", "pdf"])
df["name"] = [f[0:4] for f in pdf_list]
years = [f[4:8] for f in pdf_list]
df['year'] = years
df['pdf'] = pdf_list
df = df.sort_values(by='year', ascending=False)
df["pdf"]
sale = []
profit =[]
for pdf in df['pdf']:
i=0
#year = pdf[4:9]
doc = fitz.open(pdf) #打开pdf
text = [page.getText() for page in doc]
text = ''.join(text)
p_re = re.compile('(?<=\n)营业总?收入(?\w?)?\s?\n?([\d+,.]*)\s\n?')
revenue = p_re.search(text).group(1)
revenue = revenue.replace(',','') #把revenue里的逗号去掉
sale.append(revenue)
profit_gain = profit_data_line(pdf)
profit_gain = profit_gain.split("\n")
profit_gain = profit_gain[1]
profit.append(profit_gain)
data = pd.DataFrame()
data["sale"]=sale
data["profit"]=profit
data.index=df["year"]
data = data[::-1]
data
data.to_csv(r"E:\360MoveData\Users\11200\Desktop\天齐锂业.csv")
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure()
plt.plot(data.index,data["sale"].astype(float),c="c")
plt.title("天齐锂业营业收入")
plt.grid()
plt.show()
plt.figure()
plt.plot(data.index,data["profit"].astype(float),c="c")
plt.title("天齐锂业每股收益")
plt.grid()
plt.show()

